 EN
EN JP
JP KR
KR
LLM(大規模言語モデル)とは?AIの進化を支える知能の仕組みと可能性
AI技術はここ数年で急速に発展し、私たちの生活や仕事の在り方を根本から変えつつあります。その中心に位置するのが「LLM(大規模言語モデル)」です。人間の言語を理解し、意味を推論し、自然な文章を生み出すこの技術は、これまでのAIの枠を超えた知的能力を示しています。
LLMは、単なる自動翻訳や検索支援にとどまらず、文章生成、要約、創作、プログラミング支援など、言語に関わるあらゆるタスクをこなす「言語の総合知能」として注目を集めています。その応用範囲は、教育、医療、法律、マーケティングなど、業界を問わず拡大し続けています。
本記事では、LLMとは何か、その基本的な仕組みや学習方法、実際の活用例、そして社会に与える影響までを体系的に解説します。AI時代を理解するうえで欠かせないこの技術を、基礎から深く掘り下げていきます。
1. LLM(大規模言語モデル)とは?
LLMとは、「Large Language Model」の略称で、大量のテキストデータを学習して言語パターンを理解・生成するAIモデルのことを指します。
これまでのAIが特定の用途に限定されていたのに対し、LLMは汎用的な知識を持ち、あらゆる言語タスクに柔軟に対応できる点が特徴です。
学習対象はニュース記事、小説、論文、SNS投稿など多岐にわたり、人間の言語使用の文脈や意味、感情の微妙な違いまで統計的に捉えることが可能です。
2. LLM(大規模言語モデル)の仕組み
LLMが自然な言語を理解し、文脈に沿った文章を生成できるのは、内部で行われる多段階の処理によるものです。これらの処理は、①トークン化、②ベクトル化、③ニューラルネットワークによる学習、④文脈理解、⑤デコードという5つの主要ステップで構成されています。それぞれの工程がどのように機能し、言語理解を支えているのかを順に説明いたします。
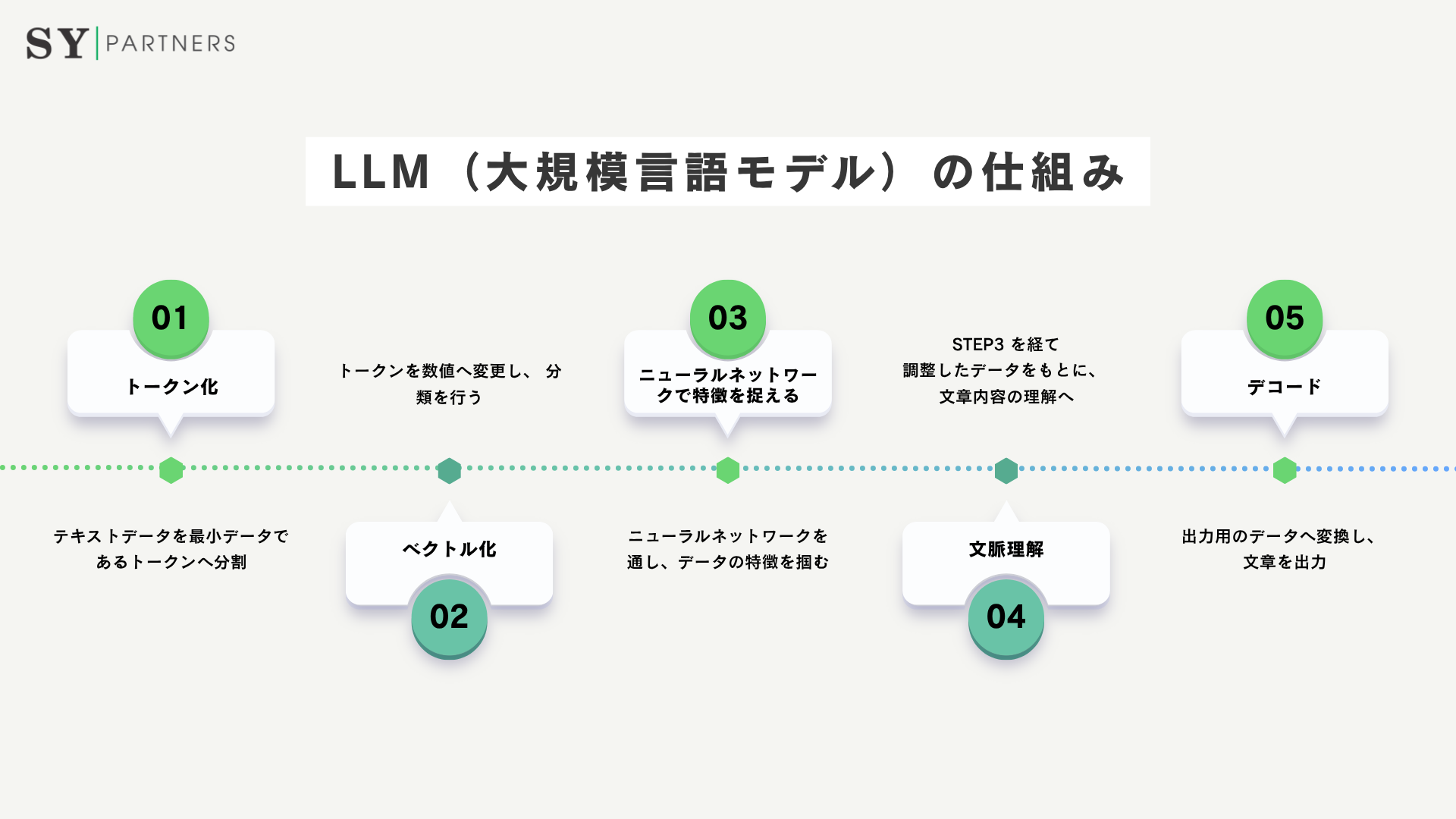
2.1 トークン化(Tokenization)
最初の工程は「トークン化」です。テキストをAIが処理しやすい最小単位に分割し、データ構造として整理いたします。例えば「AIモデル」という語は、「A」「I」「モデル」といった複数のトークンに変換されます。トークン化を行うことで、モデルは言語のパターンをより細かく学習できるようになります。
また、トークン化の方法はモデルや言語体系によって異なります。単語単位で分割するだけでなく、意味を保ちながら部分的に分解する手法(サブワード分割)が多くのモデルで採用されています。この仕組みにより、未知の語彙にも柔軟に対応でき、より正確な文理解が可能になります。
2.2 ベクトル化(Vectorization)
次に、トークン化されたデータを数値の集合である「ベクトル」に変換いたします。AIは数値情報のみを扱うため、文字や単語を数学的空間に写像する工程が必要です。この際、単語間の意味的な距離や関連性を保つよう設計されており、意味の近い単語は空間上でも近い位置に配置されます。
たとえば「王 − 男 + 女 ≒ 女王」という関係が示すように、ベクトル化は言語の意味構造を数値として捉えることを可能にいたします。これにより、モデルは単なる記号列としてではなく、「意味を持つデータ」として言語を理解できるようになります。
2.3 ニューラルネットワークを通した学習
ベクトル化されたデータは、ニューラルネットワークに入力されます。特にLLMでは、「トランスフォーマー」と呼ばれる構造が採用されており、文章全体の単語間関係を同時に処理できる点が特徴です。これにより、モデルは長い文脈の中で単語同士の依存関係を把握し、より自然な構文理解を実現いたします。
学習過程では、膨大なテキストデータを解析し、「どの単語がどの文脈で出現するか」「どのような語が共起しやすいか」といった統計的傾向を獲得いたします。この学習を通して、モデルは言語の構造だけでなく、文脈上の意味の流れや論理展開も学ぶことができます。
2.4 文脈(コンテキスト)理解
学習を終えたLLMは、単語や文を単独で処理するのではなく、前後の関係を踏まえた「文脈(コンテキスト)」として理解いたします。たとえば「りんごを食べる」と「食べられたりんご」では、「りんご」の役割が異なりますが、モデルはその差を文全体の構造から正確に判断いたします。
この文脈理解の能力こそ、LLMが自然で一貫性のある文章を生成できる最大の理由です。文法的整合性に加え、発話の意図、感情の流れ、主題の変化なども考慮しながら、最適な言葉選びを行います。結果として、人間が書いたような滑らかな表現が実現されるのです。
2.5 デコード(出力ベクトルをテキストに変換)
最後の工程は「デコード」です。モデルが内部で生成した出力ベクトルをもとに、再び人間が読めるテキストへ変換いたします。AIは次に現れる単語を確率的に予測しながら、一語ずつ文章を構築していきます。このプロセスを連続的に行うことで、文脈を維持した自然な言語生成が可能になります。
デコードは単なる数値の変換ではなく、「文脈に基づく選択と生成」を繰り返す知的な過程です。そのため、同じ入力であっても生成結果が毎回異なる場合があります。これは、モデルが単なる記憶装置ではなく、確率的推論を通して言語を創造していることを示しています。
LLMの仕組みは、トークン化からデコードに至るまで、数理的処理と意味的理解を組み合わせた極めて高度な構造で成り立っています。これら5つのステップを通じて、AIは「言葉を数値として理解し、意味として再構築する」能力を獲得いたします。
このメカニズムこそが、LLMが翻訳、要約、検索、対話、創作など多様なタスクに対応できる理由です。言語の背後にある文脈や意図を統計的に把握し、的確に表現へと変換する力が、現代のAIを支える中核的知能となっています。
3. LLM(大規模言語モデル)と生成AIとの違い
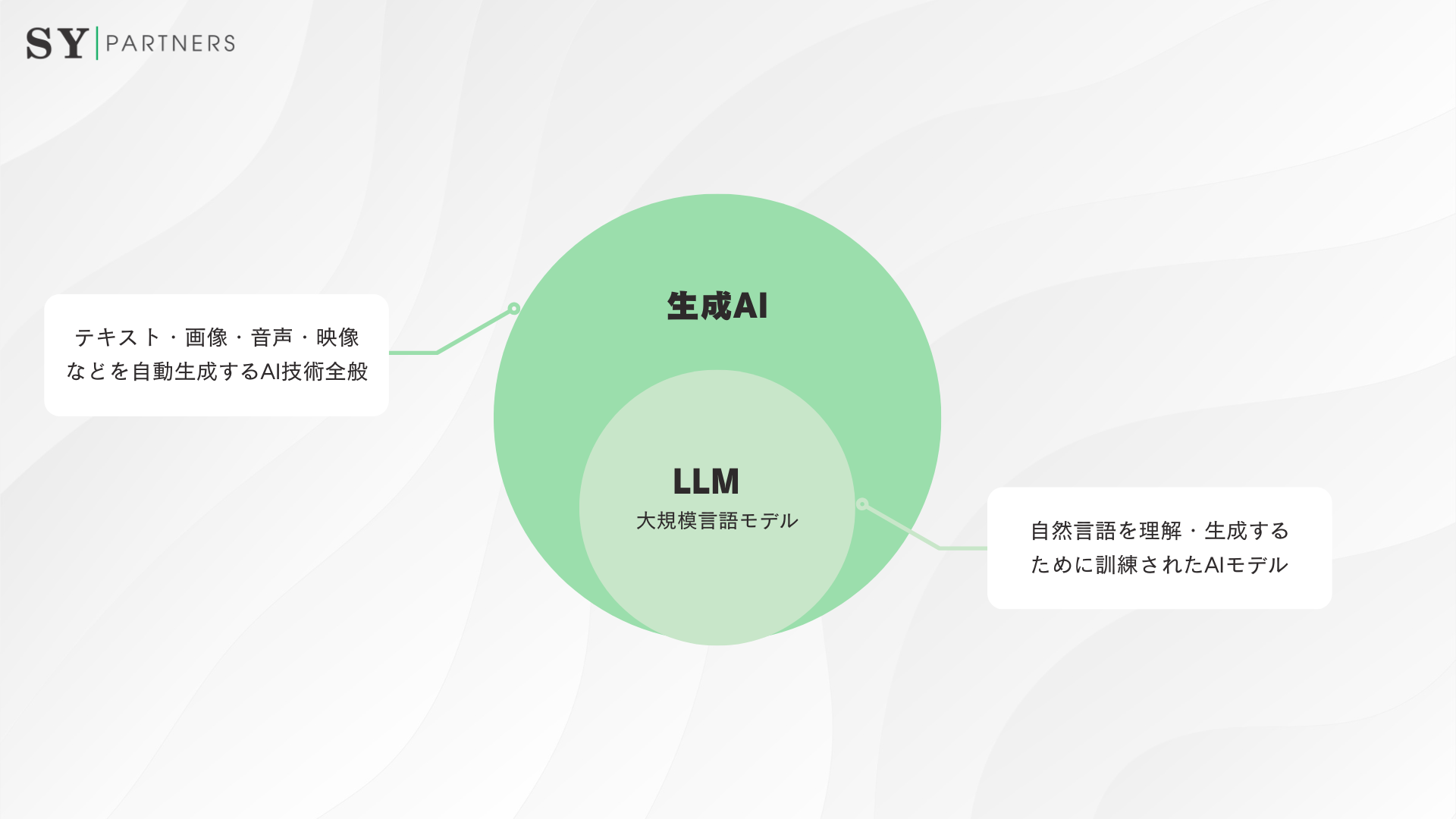
ここでは、LLMと、近年注目を集めている「生成AI」との違いについて整理いたします。これらの用語は似ているように見えますが、それぞれの概念や役割には明確な区別があります。
以下の解説では、生成AIとの関係と違いを確認し、具体的に見ていきます。
「生成AI(Generative AI)」とは、テキスト・画像・音声・動画など、さまざまな形式のコンテンツを自動生成するAI技術全般を指します。一方、LLM(大規模言語モデル)は、その中でも自然言語を扱うAIに特化した技術基盤です。つまり、LLMは生成AIを支える「中核エンジン」といえます。
以下の表は、両者の主な違いをまとめたものです。
比較項目 | LLM(大規模言語モデル) | 生成AI(Generative AI) |
| 定義 | 自然言語を理解・生成するために訓練されたAIモデル | テキスト・画像・音声・映像などを自動生成するAI技術全般 |
| 対象領域 | 言語データ(文章、対話、要約など) | 多様なメディア形式(テキスト、画像、音声、3Dなど) |
| 技術構造 | トランスフォーマー構造を基盤とするニューラルネットワーク | LLMや拡散モデル(Diffusion Model)など、複数の技術を包含 |
| 代表的なモデル | GPTシリーズ、PaLM、Claude、Geminiなど | ChatGPT、DALL·E、Midjourney、Soraなど |
| 主な用途 | 文章生成、要約、翻訳、質問応答、コード生成など | テキスト生成に加え、画像や音声などマルチモーダル生成 |
| 役割 | 生成AIの中核エンジンとして言語処理を担う | LLMなど複数のモデルを統合し、人間にとって有用な出力を生成する枠組み |
要するに、LLM(大規模言語モデル)は生成AIの中核的基盤をなす要素技術であり、生成AI全体の知的機能を支える中枢的役割を果たしています。
LLMは膨大なテキストデータをもとに言語理解・推論・生成を行う「認知的エンジン」に相当し、一方の生成AIは、その言語的知能を統合し、テキスト・画像・音声・動画など多様なメディア表現を創出する「統合的創造システム」として機能します。
4. LLMの活用分野

LLM(大規模言語モデル)は、自然言語を理解し生成する能力を活かし、あらゆる産業や知的活動の領域に応用されています。単なる自動応答や文章生成を超えて、知識処理、意思決定支援、創造的活動の拡張など、多様な価値を生み出しています。
ここでは、ビジネス、教育、クリエイティブ、医療、法務、科学技術の6分野に焦点を当て、具体的な活用例とその意義を考察いたします。
4.1 ビジネスと業務効率化
企業活動において、LLMは業務の自動化と知識共有の高度化を同時に実現しています。社内の問い合わせ対応を自動化するチャットボットや、会議記録を即座に要約するツール、カスタマーサポートの応答最適化システムなどが代表的な例です。これらの仕組みにより、人手を要していた情報整理や報告業務の負担が軽減され、従業員はより付加価値の高いタスクに集中できるようになりました。
さらに、経営戦略やマーケティング分析にもLLMが活用されています。大量の市場データや顧客フィードバックを解析し、消費傾向やニーズを自然言語で要約・報告することが可能になりました。これにより、企業はデータドリブンな意思決定を迅速に行えるようになり、競争優位性の確立にもつながっています。
4.2 教育と研究支援
教育分野では、LLMが個別学習の支援ツールとして導入されつつあります。学習者の理解度や質問内容に応じて、柔軟に説明を変えることができるため、個々に最適化された学習環境の実現が可能です。自動添削や課題フィードバック、教材生成などにも応用され、教育者の負担軽減と教育の質的向上を両立させています。
研究の現場でも、LLMは文献検索や要約、翻訳の自動化に大きな貢献をしています。論文の下書きや研究計画書の草稿を支援する機能も登場しており、研究者がより本質的な思考や発想に専念できる環境が整いつつあります。今後は、学術知識の統合や仮説生成など、研究そのものを加速する知的インフラとしての役割が期待されています。
4.3 クリエイティブ
クリエイティブ分野では、LLMが人間の発想を補完し、新たな表現の可能性を広げています。広告コピーやキャッチフレーズの生成、脚本や小説の構成案作成、映像作品のストーリープランニングなど、創作活動の多様な段階で利用されています。AIが提示する多角的なアイデアを起点として、人間の創造性をさらに高める効果が確認されています。
一方で、LLMが生み出す文章や物語は、人間の感性を刺激しながらも、創作の主体性をめぐる新たな議論を呼び起こしています。AIと人間が共同で作品を生み出す「共創(co-creation)」という考え方が広まり、創造行為の定義そのものが変化しつつあります。創作の領域では、LLMが“道具”から“共作者”へと進化しているのです。
4.4 医療・ヘルスケア
医療領域では、LLMが臨床文書の自動要約や診療記録の整理に用いられています。医師は診断や治療に集中できるようになり、カルテ入力などの事務的作業を大幅に削減できるようになりました。また、LLMが学習した医療文献をもとに、症例比較や診断補助を行う試みも進んでいます。
さらに、患者向けの説明資料や医療情報の平易化にも活用され、専門用語をわかりやすく翻訳するツールとして機能しています。医療従事者と患者の間のコミュニケーションを改善し、情報の非対称性を減らすことで、より安心できる医療環境の構築に貢献しています。
4.5 法務・行政
法務の現場では、LLMが契約書のレビュー、リスク分析、法令検索などに利用されています。文書構造を解析し、類似条項や不備を自動的に抽出することで、法務担当者の確認作業を効率化できます。これにより、契約審査のスピードが大幅に向上し、法的リスクの早期発見が可能となっています。
行政分野においても、LLMは政策文書の作成支援や住民対応の自動化に活用されています。行政文書を自然言語で生成・要約する機能は、職員の作業負荷を軽減すると同時に、公共情報の透明性向上にも寄与しています。AIによる説明責任を担保する仕組みづくりも、今後のガバナンスにおける重要課題です。
4.6 サイエンス・テクノロジー
科学技術の分野では、LLMが研究開発プロセスを効率化しています。自然科学分野では、論文データからの知識抽出や仮説形成の補助、数理モデルの自動記述などに応用されています。また、生成AIと連携した実験設計の自動化も進み、研究のスピードと再現性が大幅に高まっています。
エンジニアリングやソフトウェア開発では、コード生成やバグ修正の支援にLLMが活用されています。自然言語による指示から動作するプログラムを生成する仕組みは、開発の民主化を推進し、専門知識を持たない人でも開発プロセスに参加できる可能性を広げています。これにより、科学技術の創造サイクルそのものが変革の段階に入りつつあります。
LLMの活用領域は、ビジネスから科学技術まで広範囲にわたっており、すでに社会基盤の一部となりつつあります。各分野で共通しているのは、情報処理の効率化とともに、人間の思考や創造性を拡張する方向へと技術が進化している点です。
5. LLMがもたらす影響

LLM(大規模言語モデル)の進化は、AIの技術的発展を超えて、社会の構造や人間の知的活動のあり方そのものを変えつつあります。
その影響は、ビジネス、教育、経済、倫理、そして文化など多岐にわたり、私たちの思考や働き方にも深く浸透しています。
以下では、LLMがもたらす主要な六つの側面を中心に、その変化と課題を詳しく見ていきます。
5.1 ビジネス領域における生産性の変革
LLMは、ビジネスの効率性と知的生産性を大きく変える要因となっています。文章の自動生成、要約、情報整理、顧客対応などの業務が自動化され、従業員はより創造的な仕事に集中できるようになりました。
特に、社内文書の検索支援やナレッジ共有の領域では、LLMを基盤とした検索エンジンやFAQシステムが導入され、情報アクセスのスピードと精度が向上しています。こうした変化は、単なる作業効率の改善ではなく、知識の循環そのものを再構築する動きにつながっています。
5.2 教育・研究分野へのインパクト
教育の分野では、LLMが個々の学習者に合わせた教材生成や自動添削、理解度に応じた質問応答を可能にしています。これにより、画一的な教育モデルから、学習者中心の「パーソナライズ教育」へと転換が進んでいます。
また、研究領域でも、文献要約や仮説形成、データ解析の自動支援など、知的生産のプロセスにおいてLLMの応用が進んでいます。これらは研究者の思考を補助する「知識共創ツール」としての価値を示しており、学術活動そのものの在り方を変えつつあります。
5.3 コミュニケーション構造の変化
LLMを活用したチャットボットや会話システムの普及により、人間とAIの関係性は新たな段階に入りました。行政機関、企業、医療現場などでは、問い合わせ対応や情報提供をAIが担うケースが増え、人と機械の間のコミュニケーションが日常化しています。
こうした変化は、ユーザー体験を大きく向上させる一方で、「AIとの対話が人間のコミュニケーション習慣にどのような影響を及ぼすか」という社会的・心理的課題も浮き彫りにしています。AIが対話の主体となる時代において、言語の信頼性と人間らしい対話の価値をどう維持するかが今後の焦点となります。
5.4 経済・産業構造への波及効果
LLMの導入は、企業の業務効率化にとどまらず、産業全体の競争構造を再定義しています。AIを活用した自動コンテンツ生成やマーケティング分析、ソフトウェア開発の自動化などが急速に進み、知識産業の生産性モデルが変化しています。
同時に、AIが人間の労働に与える影響も顕著になっています。単純な情報処理業務はAIによって代替される一方で、創造的思考や戦略的判断を求められる仕事の価値は上昇しています。このシフトは、職業構造の再編成と新しい雇用機会の創出を同時に促進するものとなっています。
5.5 倫理・信頼性・情報ガバナンスの課題
LLMは強力な生成能力を持つ反面、倫理的・社会的課題も抱えています。誤情報の拡散、著作権侵害、偏見の再生産などのリスクが指摘されており、AI出力の信頼性確保が重要なテーマとなっています。
特に、LLMがどのようなデータを学習しているのか、その透明性と説明可能性(Explainability)は、今後のAIガバナンスの核心をなす要素です。倫理的利用を確保するためには、開発者・利用者・社会全体が責任を共有し、持続可能なルール形成を進める必要があります。
5.6 文化・表現領域への影響
LLMは、文化的・創造的表現にも大きな変化をもたらしています。AIが詩や物語、広告コピー、脚本などを生成するようになり、人間とAIが共同で創作を行う「共創」の時代が始まりました。
こうした現象は、芸術や表現における“創造性”の定義そのものを問い直しています。AIが創作活動に参加することで、人間の想像力の拡張が実現される一方、「どこまでが人間の創作なのか」という新しい哲学的課題も生まれています。文化の領域においても、AIとの共存が避けて通れないテーマとなりつつあります。
LLMの影響は、技術の枠を超えて社会全体の構造変化を促すものであり、人間の知的活動や価値観にも深い影響を与えています。ビジネスや教育などの実務領域から、倫理・文化といった抽象的領域まで、LLMは「人間の知を拡張する存在」として社会の根幹に浸透しています。
おわりに
LLM(大規模言語モデル)は、膨大なテキストデータを学習し、人間のように言語を理解・生成できるAIの中核的技術です。単なる自然言語処理の進化ではなく、「言語を通じて思考する知能」の再定義ともいえる存在であり、創造、分析、対話といった知的活動そのものをAIが担えるようになりました。この変化は、教育・研究・ビジネスなどあらゆる領域で、人間の知的作業の在り方を大きく変えつつあります。
同時に、LLMは「人とAIの協働」という新しい関係性を生み出しています。AIが人間の思考を補完し、個人や組織の創造力を拡張する時代が到来しています。私たちは今、AIと共に学び、共に成長する段階に立っています。LLMを理解することは、単なるテクノロジーの知識ではなく、未来の社会における「知の共創」を考えるための第一歩となります。
よくある質問
従来のAIは特定のタスクに最適化され、画像分類や音声認識など、限られた目的に対応するよう設計されていました。たとえば「犬と猫を区別する」など、用途ごとに別々のモデルを構築する必要がありました。
一方、LLM(大規模言語モデル)は、言語を理解し生成する汎用的な能力を持ち、翻訳、要約、質問応答、プログラミング支援など、複数のタスクを一つのモデルで処理できます。これはトランスフォーマー構造を基盤に、膨大なテキストデータから文脈や意味、推論関係を統合的に学習しているためです。
つまりLLMは、特化型AIから汎用的知能への転換を象徴する技術であり、「タスクごとのAI」から「知能としてのAI」へ進化した存在といえます。
LLMの文脈理解を支えているのは、「自己注意機構(Self-Attention)」です。これは文章全体を通して単語同士の関係性を動的に評価し、どの単語が他のどの単語に関連しているかを重みづけする仕組みです。
たとえば「彼は銀行に行って川を見た」という文では、「銀行(bank)」が金融機関を意味するのか、それとも川辺(riverbank)を指すのかは文脈によって決まります。LLMは前後の単語の関係性を確率的に分析し、最も自然な意味を推定します。
この仕組みにより、LLMは単なる単語列の処理ではなく、「意味の流れ」を把握して理解することが可能になります。人間の読解力を数学的に再現している点が大きな特徴です。
ChatGPTは、LLM(たとえばOpenAIのGPTシリーズ)を基盤とした応用レイヤー(アプリケーション)です。LLM自体は言語を理解・生成する中核的な知能モデル、いわば“脳”に相当します。
これに対してChatGPTは、その上に対話管理、メモリ制御、ユーザーインターフェース、フィードバック最適化などの機能を追加した「製品システム」です。また、人間の評価をもとにした強化学習(RLHF:Reinforcement Learning from Human Feedback)により、自然で安全な応答を生成できるよう調整されています。
したがって、LLMはChatGPTの「頭脳部分」であり、ChatGPTはそれを「人が使いやすい形に実装した対話型知能」といえます。
幻覚とは、モデルが存在しない情報をあたかも事実のように生成してしまう現象を指します。これは、LLMが事実データベースではなく、確率的な言語モデルとして動作していることに起因します。
つまりLLMは、過去の学習データから文法的・文脈的に自然な単語列を予測するため、内容の真偽までは判断できません。そのため、統計的には自然でも、実際とは異なる情報を出力してしまうことがあります。
この問題に対しては、検索エンジンや企業のナレッジベースと連携し、事実を参照しながら回答を生成する「RAG(Retrieval-Augmented Generation)」という手法が有効です。今後のLLMは、生成能力に加えて「信頼性」と「検証性」を強化する方向に進化していくと考えられます。
今後のLLMの発展は、次の3つの方向に集約されると予測されます。
- マルチモーダル化(Multimodal Integration)
テキストだけでなく、画像・音声・動画・センサー情報を統合的に理解・生成する能力を持つLLMが登場しています(例:OpenAI GPT-4o、Google Geminiなど)。 - 領域特化型LLM(Domain-Specific Models)
医療、法務、教育など、特定分野の知識を深く学習したLLMが増え、業界ごとの専門AIが普及します。 - 自己学習・自己改善(Self-Improving Systems)
人間の介入を減らし、自らデータを収集・最適化し、推論能力を進化させる「自己進化型AI」への研究が進んでいます。
これらの方向性は、AIが単なる支援ツールではなく、人間の知的パートナーとして機能する未来を示唆しています。
LLMの進化は、もはやテクノロジーの発展だけでなく、人間の知の拡張そのものを意味しています。
