 EN
EN JP
JP KR
KR
自然言語理解(NLU)とは?仕組み、技術、ビジネスでの活用可能性を解説
自然言語処理(NLP)の中核技術である自然言語理解(NLU: Natural Language Understanding)は、テキストや音声から文脈や意図を正確に読み取るAI技術です。単語の処理にとどまらず、チャットボットや音声アシスタント、感情分析など、対話型AIの基盤として多くのビジネス領域で活用されています。企業においては、顧客対応の自動化やデータ分析の効率化を通じて、生産性向上やコスト削減に貢献しています。
近年、デジタルトランスフォーメーション(DX)の加速により、日本企業でもNLUの導入が進み、顧客体験の向上や業務プロセスの最適化が期待されています。本記事では、NLUの仕組みや技術、ビジネス活用事例、導入時の課題を解説し、企業がNLUを通じて競争力を高めるためのヒントを紹介します。
1. 自然言語理解(NLU)とは?
自然言語理解(NLU: Natural Language Understanding)は、自然言語処理(NLP: Natural Language Processing)のサブフィールドであり、コンピュータが人間の言語(テキストや音声)を理解し、その背後にある意味や意図を抽出する技術です。
NLPが言語データの処理全般をカバーするのに対し、NLUは特に「理解」に焦点を当て、文脈やユーザーの目的を把握します。たとえば、ユーザーが「明日の天気は?」と尋ねた場合、NLUは単に単語を解析するだけでなく、「天気予報を求めている」という意図を認識し、適切な応答を生成するプロセスを支えます。
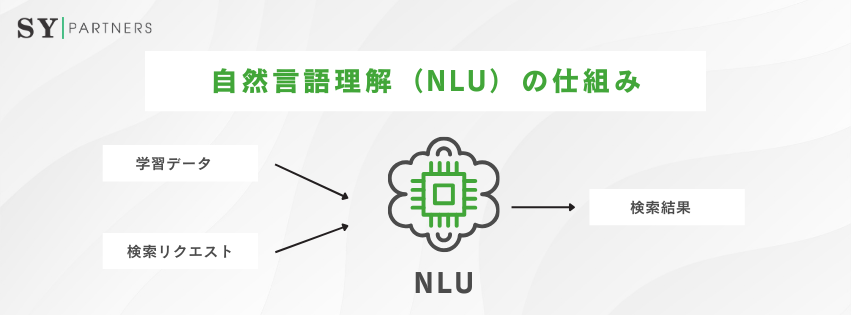
NLUは、以下の主要な要素で構成されます:
- 意図認識(Intent Recognition):ユーザーの発話やテキストの目的を特定。例:「ピザを注文したい」→注文意図を認識。
- エンティティ抽出(Entity Extraction):テキストから具体的な情報(例:人名、場所、日付)を抽出。例:「午後2時の予約」→時間とタスクを特定。
- 文脈理解(Context Understanding):会話の履歴や背景情報を参照し、適切な応答を生成。例:過去のやり取りを基にカスタマイズされた提案を提供。
NLUの応用例には、音声アシスタント(Siri、Alexa)、カスタマーサポートのチャットボット、感情分析、自動翻訳などがあり、ビジネスの効率化や顧客体験の向上に貢献しています。
2. NLUの仕組みと主要技術
NLUは、複雑なプロセスを通じて人間の言語を機械が理解できる形式に変換します。その仕組みは、以下のステップと技術で構成されています:
2.1 テキストの前処理
NLUの第一歩は、テキストや音声データを機械が処理しやすい形式に整えることです。主な前処理技術には以下が含まれます:
- トークン化(Tokenization):文章を単語やフレーズに分割。日本語では、形態素解析を用いて「走る」「走った」を適切に処理。
- 正規化(Normalization):大文字・小文字の統一や、記号・ノイズの除去を行い、データの一貫性を確保。
- ストップワード除去:分析に不要な単語(例:「は」「の」)を削除し、重要な情報に焦点を当てる。
2.2 特徴抽出
前処理されたデータから、意味を理解するための特徴を抽出します。以下のような手法が一般的です:
- ワードエンベディング(Word Embeddings):単語を意味的なベクトル空間に変換し、類似性を捉える(例:Word2Vec、BERT)。
- 構文解析(Syntactic Analysis):文の文法構造を解析し、主語や述語の関係を特定。
- 意味解析(Semantic Analysis):単語やフレーズの意味を文脈に基づいて解釈。
2.3 意図とエンティティの認識
NLUの中核は、ユーザーの意図と重要なエンティティを特定することです。たとえば、「東京で明日の天気予報を教えて」と言われた場合、NLUは「天気予報の提供」という意図と、「東京」「明日」というエンティティを抽出します。
これには、機械学習(ML)モデルや深層学習(例:トランスフォーマーモデル)が活用され、大量のトレーニングデータでパターンを学習します。
2.4 文脈の統合
過去の会話や外部データを参照し、文脈を理解します。たとえば、ユーザーが「次は大阪の天気」と続けた場合、NLUは「天気予報」という意図を継承し、「大阪」を新たなエンティティとして認識。これにより、自然で流れるような対話が可能になります。
3. NLUのビジネス活用8選
NLUは、ビジネスプロセスの効率化や顧客体験の向上に多大な貢献をしています。以下は、日本およびグローバル市場での具体的な活用事例8選です。
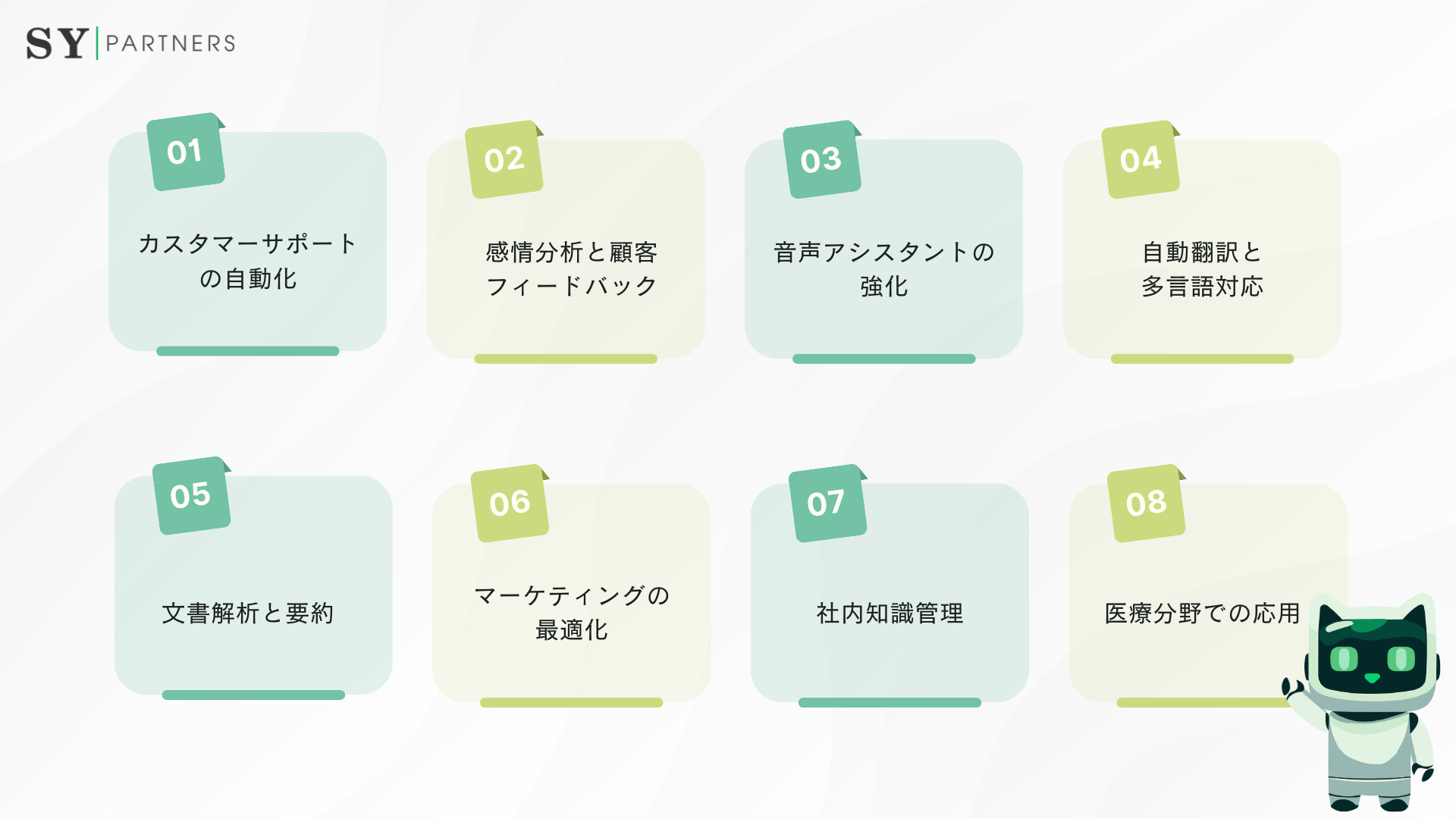
3.1 カスタマーサポートの自動化
NLUを活用したチャットボットが、顧客の問い合わせをリアルタイムで処理。日本の小売企業が、「返品方法は?」という質問に、NLUで意図を認識し、適切な手順を案内。24時間対応で顧客満足度を向上させます。
3.2 感情分析と顧客フィードバック
SNSやレビューから顧客の感情(ポジティブ、ネガティブ)を解析。日本のホテル業界が、NLUで顧客レビューを分析し、サービスの改善点を特定。たとえば、「部屋が狭い」という不満を迅速に検出します。
3.3 音声アシスタントの強化
NLUは、AlexaやGoogle Assistantのような音声アシスタントの基盤。日本のスマートホーム企業が、ユーザーの「電気を消して」という指示を意図として認識し、デバイスを制御。自然な対話を実現します。
3.4 自動翻訳と多言語対応
NLUを活用した翻訳システムが、文脈を考慮した高精度な翻訳を提供。日本の輸出企業が、海外顧客とのメールでNLUを用いて英語から日本語への翻訳を自動化。誤訳を減らし、コミュニケーションを円滑化します。
3.5 文書解析と要約
契約書やレポートから重要な情報を抽出。日本の法務部門が、NLUで契約書のリスク条項を特定し、要約を生成。手作業の時間を大幅に削減します。
3.6 マーケティングの最適化
NLUで顧客データを分析し、パーソナライズされたキャンペーンを設計。日本の広告企業が、顧客の購買履歴やSNS投稿を基に、ターゲット広告を生成。エンゲージメント率を向上させます。
3.7 社内知識管理
NLUを活用し、社内ドキュメントやメールから情報を抽出。日本のコンサルティング企業が、過去のプロジェクトデータをNLUで整理し、新規提案の参考に。情報検索の効率が向上します。
3.8 医療分野での応用
NLUは、医療記録や患者のフィードバックを解析。日本の病院が、患者の問診データをNLUで分析し、診断支援や優先順位付けを実施。医師の負担を軽減します。
4. NLUの料金モデルと導入方法
自然言語理解(NLU)をビジネスに導入する際には、単に技術的な優位性を評価するだけでなく、どのような料金体系で提供されているかを理解することが重要です。NLUは現在、オープンソースからクラウドAPI、さらにはエンタープライズ向けソリューションまで多様な形態で提供されており、導入企業の規模や目的に応じて最適な選択肢が異なります。以下では、それぞれの料金モデルとその特長を比較し、具体的な導入ヒントとあわせて紹介します。
ソリューション | 価格 | 主な特徴 | 用途例 |
| オープンソース(Rasa NLU) | 無料 | ・完全にカスタマイズ可能 ・ローカル環境で実行可能 ・意図認識・エンティティ抽出など基本機能を搭載 | スタートアップ企業、大学や研究機関、プロトタイプ開発向け |
| クラウドAPI(AWS Comprehend) | 従量課金制(例:0.002ドル/100文字) | ・感情分析や固有表現認識に対応 ・スケーラブルでありながらシンプルに統合可能 ・クラウドベースで導入が容易 | 中小企業、アプリケーション開発者 |
| エンタープライズ(Cognigyなど) | 要問い合わせ(個別見積もり) | ・音声入力を含む高度な対話管理機能 ・大規模データ対応 ・高いセキュリティ要件にも適合 | 大企業、金融・通信・医療などセキュリティ重視の業界 |
導入のヒント
- オープンソースで試用:Rasa NLUなど無料ツールで初期テストを実施。
- クラウドAPIの活用:AWSやGoogle CloudのNLUサービスで、スケーラブルな導入を。
- トレーニングデータの充実:高精度な意図認識には、豊富な学習データが必要。
- 段階的導入:小規模なプロジェクトで効果を検証後、全社展開を検討。
5. NLUの限界と課題
自然言語理解(NLU)は非常に高機能な技術として注目されていますが、すべての課題が解決されているわけではありません。現段階では、言語的・技術的・倫理的な側面においていくつかの重要な制約が存在しています。本章では、NLUを実際の業務に活用するうえで留意すべき主な課題とその背景について詳しく解説します。
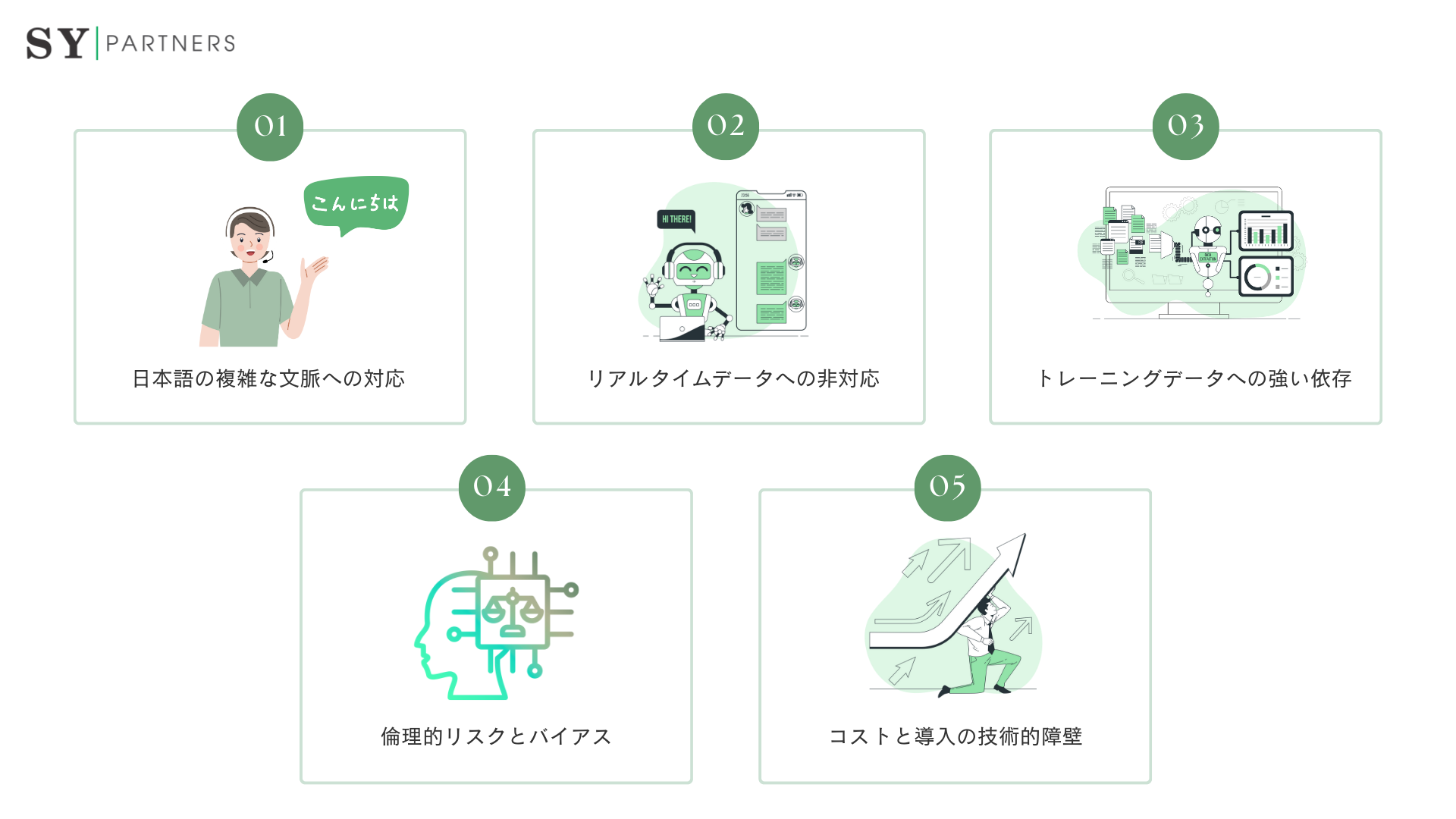
5.1 日本語の複雑な文脈への対応
日本語は、他言語と比べて文脈に強く依存し、かつ主語の省略や敬語・あいまい表現が多いため、NLUにとって非常に扱いにくい言語です。たとえば、同じ「結構です」という表現でも、文脈によって肯定にも否定にも解釈される可能性があります。実際、X(旧Twitter)などのSNSでは「日本語の意図認識が不自然」といった声が散見されており、言語モデルのローカライズが今後の改善課題とされています。
5.2 リアルタイムデータへの非対応
SNS投稿やニュース速報など、刻々と変化するリアルタイムデータの処理には、NLU単体では限界があります。最新トピックへの反応や即時対応が求められる場面では、補助的に情報検索エンジンやトピック抽出ツールを併用する必要があります。NLUはあくまで文脈の理解に強みがあるため、速報性の高い情報処理には別のアプローチとの連携がカギになります。
5.3 トレーニングデータへの強い依存
NLUの性能は、与えられるトレーニングデータの量と質に大きく左右されます。しかし日本の多くの企業では、業界ごとの専門用語や独自表現が多く、それに対応したデータの整備が十分でない場合もあります。その結果、意図認識やエンティティ抽出の精度が思ったほど上がらないという課題に直面することも少なくありません。
5.4 倫理的リスクとバイアス
NLUモデルは、学習したデータに含まれるバイアスをそのまま引き継いでしまう可能性があります。これにより、たとえば特定の文化や性別に対する偏見を含んだ応答が生成されてしまうリスクがあります。また、ユーザーの意図を誤解して不適切な回答を返してしまうことで、誤解やトラブルを招く可能性もあります。そのため、特に公共性の高い分野では、NLUの出力結果を人間がチェック・監修する仕組みが必要です。
5.5 コストと導入の技術的障壁
高度なNLUソリューションの多くは高額であり、エンタープライズ向けの製品になると、導入コストだけでなく、運用やメンテナンスにも高い技術的スキルが求められます。中小企業にとっては、こうした初期障壁が導入の大きなハードルになる場合も多く、社内に技術リソースが不足している場合は外部パートナーとの連携が不可欠となるでしょう。
NLUは強力な技術ですが、日本語対応やリアルタイム性、学習データの整備、倫理・コスト面などに課題があります。こうした制約を理解し戦略的に導入すれば、大きな成果も期待できます。今後の発展を見据えつつ、現実的な視点で活用する姿勢が重要です。
終わりに
自然言語理解(NLU)は、コンピュータが人間の言語を深く理解し、文脈や意図を把握する技術です。カスタマーサポート、チャットボット、感情分析、音声インターフェースなど、さまざまな分野で活用が進んでおり、業務の効率化やユーザー体験の向上に寄与しています。
一方で、言語の多様性やデータ品質、倫理的な配慮など、導入にはいくつかの課題も伴います。オープンソースの活用やクラウドAPIによる試行、高品質なデータの整備、継続的な改善が成功の鍵です。今後は、生成AIとの連携やモデルの進化により、さらに幅広い応用が期待されます。
