 EN
EN JP
JP KR
KR
JSONとは?定義・構造・データ型・用途・関連技術との違いまで徹底解説
JSONはデータ交換を目的として広く用いられる軽量フォーマットであり、構造が明確で取り扱いやすい点が特性として知られます。階層構造に基づき、複数のデータ型を組み合わせて表現できるため、システム間通信に適した形式として確立しています。こうした特徴により、データを読み書きする環境を問わず利用できる柔軟性を持ちます。
またJSONは、単純な文字ベースの構造でありながら、オブジェクトや配列を中心とした汎用的なデータ表現を可能にします。システム構造が異なる環境間であっても、データ内容を共通規格で扱えるため、交換コストを削減できる点が技術的優位性を高めています。可読性を重視した形式を持つことで、解析処理においても直感的な理解がしやすくなります。
本記事では、JSONの定義を起点にして、構造的特徴、データ型、用途、関連技術との違いを段階的に整理し、データ交換形式における基盤概念を明確化します。
1. JSONとは
JSON(JavaScript Object Notation)は、テキストベースのデータ交換形式であり、キーと値の組み合わせ、配列、階層構造を用いて情報を表現します。言語に依存しない形式として扱われ、さまざまなプラットフォームでの利用が可能です。オブジェクト指向の概念に基づいた構造になっており、データを論理的に整える仕組みが備わっています。
JSONは人間にとって読みやすい構造を保ちながら、機械が効率的に解析できるよう設計されている点も特徴です。括弧・コロン・カンマといった明確な記号によって階層を示し、複数のデータ型を統合します。
JSONが選択される理由
JSONが多く採用される理由として、まず形式が軽量である点が挙げられます。余計なタグや冗長な構文が少なく、データの記述が簡潔に行えるため、通信コストや処理負荷の低減につながります。
また、データ構造の明確性もJSONの特徴です。キーと値のペアによる構造化により、階層型やドキュメント型のデータも直感的に表現でき、システム間でのデータ交換や解析が容易になります。
さらに、処理速度の高さや汎用性の高さから、フロントエンドとサーバー間の通信をはじめ、さまざまなシステムで標準的に利用されています。これらの理由から、JSONは現代のWeb開発やアプリケーション開発において広く採用されるデータ形式となっています。
JSONデータフロー
JSONデータがサーバーからクライアントへ受け渡される流れを、下の図で視覚的に確認できます。サーバー側でのオブジェクト生成から文字列化、そしてクライアント側でのパースまで、処理のつながりがひと目で把握できるはずです。
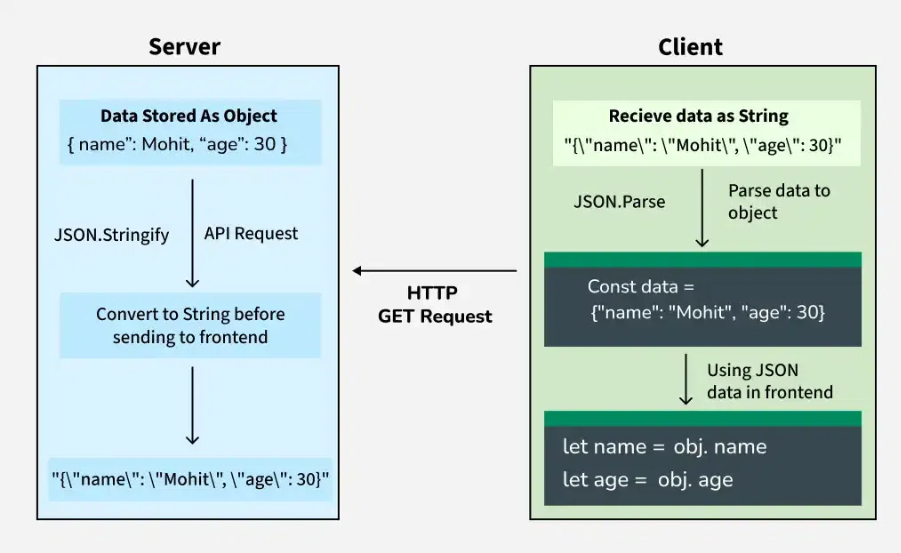
この一連のステップを理解しておくことで、API 通信の挙動だけでなく、データがどのようにフロントエンドの処理へ橋渡しされるのかまで、より体系的にイメージできるようになります。
2. JSONの特徴
JSONは、システム間でのデータ交換を効率化するための標準的なデータ表現形式です。その特徴を以下の観点で整理します。
特徴 | 説明 |
可読性 | 人間にも理解しやすい構造で、編集や調整が容易。 |
シンプルな構文 | 波括弧や配列形式を用い、直感的にデータ構造を表現可能。 |
言語非依存 | テキスト形式のため、どのプログラミング言語でも生成・解析が可能。 |
軽量性 | XMLなどに比べ記述量が少なく、通信負荷を低減。 |
拡張性 | 入れ子構造や配列を組み合わせ、複雑なデータ構造も表現可能。 |
標準化 | RFC 8259に準拠し、広く認知・利用されている形式。 |
相互運用性 | 多様なシステム間でのデータ交換に適し、一貫性を確保。 |
可逆性 | JSONを生成・解析することで、元のデータ構造を忠実に復元可能。 |
これらの特徴により、JSONは軽量かつ扱いやすいデータ形式として、WebやAPI、アプリケーション間連携で幅広く活用されています。
3. JSONの構造
JSON(JavaScript Object Notation)は、軽量かつ可読性の高いデータ形式で、Web API、モバイルアプリ、IoT、クラウドサービスなど、あらゆる分野でデータ交換の標準として利用されています。JSONを理解することで、データ設計の精度を高め、解析やシステム間のデータ連携を効率化できます。本章ではJSONの基本構造、各データ型の特徴と活用例について詳しく解説します。
3.1 オブジェクト構造
JSONオブジェクトは、キー(文字列)と値(任意の型)のペアで構成されます。オブジェクトは入れ子(ネスト)構造を作れるため、複雑なデータを整理して管理できます。
3.1.1 階層構造の利点
オブジェクトの階層構造により、関連する情報をまとめて管理可能です。
例(日本の地方自治体データ)
{
"Tokyo": {
"population": 14000000,
"wards": ["Shinjuku", "Shibuya", "Minato"],
"mayor": "Koike"
},
"Osaka": {
"population": 8800000,
"wards": ["Kita", "Chuo", "Naniwa"],
"mayor": "Yoshimura"
}
}
この例では、都道府県ごとの人口、区、知事情報をまとめています。APIや統計分析に便利です。
例(グローバル:国別経済データ)
{
"Japan": {"GDP": 5000, "currency": "JPY", "growthRate": 1.2},
"USA": {"GDP": 25000, "currency": "USD", "growthRate": 2.3}
}
国ごとのGDPや通貨、成長率をまとめることで、経済指標APIやデータ分析で使いやすくなります。
3.1.2 キーの一意性
オブジェクト内のキーは一意でなければならず、特定の値を正確に参照できます。
例(ユーザー情報API)
{
"userId": 12345,
"name": "Tanaka",
"email": "[email protected]",
"premiumMember": true
}
UserIdやemailが一意であることで、ユーザー情報を正確に管理できます。
3.1.3 値の多様性
オブジェクトの値には文字列、数値、真偽値、配列、別オブジェクトなど、さまざまな型を組み合わせられます。
例(旅行情報API)
{
"destination": "Paris",
"attractions": ["Eiffel Tower", "Louvre Museum"],
"annualVisitors": {"2023": 19000000, "2024": 20000000},
"isOpen": true
}
複雑な情報を一つのオブジェクトでまとめられ、フロントエンドやモバイルアプリでの利用が容易です。
3.2 配列構造
JSON配列は順序付きの要素の集合です。整数、文字列、オブジェクトなど異なる型を混在させることも可能で、リスト形式のデータ管理に適しています。
3.2.1 順序の保持
配列は要素の順序を保持するため、ランキングや時系列データ、ステップごとの記録などの管理に最適です。順序を意識したデータ設計が可能になるため、分析や表示において重要な意味を持ちます。
例(日本国内観光都市ランキング2025)
["Tokyo", "Kyoto", "Osaka", "Hokkaido"]
例(グローバル:月ごとの気温データ)
[2.5, 3.1, 7.2, 12.5, 17.8, 21.0, 25.3, 26.1, 21.7, 15.2, 9.0, 4.1]
順位や時間の順序をそのまま保持できるため、観光ガイドや気象分析などでそのまま利用可能です。
3.2.2 異なる型の混在
配列内では、文字列、数値、オブジェクト、さらに配列など、異なる型を混在させることができます。これにより、複雑なデータ構造を柔軟に表現できます。
例(国際会議参加者リスト)
[
{"name": "John", "country": "USA", "attended": true},
{"name": "Yuki", "country": "Japan", "attended": false},
"Guest Speaker"
]
例(グローバル:オンライン注文リスト)
[
{"item": "Laptop", "quantity": 1, "price": 1200.5},
"Gift Card",
{"item": "Mouse", "quantity": 2, "price": 25.0}
]
異なる型を混ぜることで、複数のデータ要素を1つの配列にまとめられ、柔軟なデータ設計が可能です。
3.2.3 ネスト配列
配列の中に配列を入れることで、多次元データやテーブル形式のデータを簡潔に表現できます。階層的なリストを扱う場合に便利です。
例(日本各県の主要都市)
[
["Tokyo", "Shinjuku", "Shibuya"],
["Osaka", "Kita", "Chuo"],
["Kyoto", "Fushimi", "Sakyo"]
]
例(グローバル:国ごとの月別平均気温)
[
["Japan", [5.2, 6.0, 10.5, 15.2, 19.8, 22.5, 26.0, 27.0, 22.5, 16.0, 11.0, 6.0]],
["USA", [-1.0, 0.5, 5.5, 11.2, 16.8, 22.0, 25.5, 24.5, 20.0, 14.0, 7.0, 1.0]]
]
ネスト配列を活用することで、階層構造や多次元データを整理して扱うことができ、統計分析やテーブル表示も簡単になります。
配列は順序を保持できる点、異なる型を混在させられる点、ネスト構造で多次元データを表現できる点が大きな特徴です。ランキング、時系列データ、階層的なリストなど、あらゆる場面で柔軟に活用できます。
3.3 基本データ型
JSONで扱える基本型は6種類で、それぞれ異なる表現力を持ちます。データの性質に応じて使い分けます。
3.3.1 文字列(String)
文字列は、テキスト情報を表現する基本型です。JSONでは、文字列は必ずダブルクオート " で囲みます。ニュースタイトルや名前、説明文など、人間が読める情報を扱う際に使用されます。
例(グローバルニュース記事タイトル)
"title": "Global AI Trends in 2025"
例(日本のニュース記事タイトル)
"title": "東京オリンピック2025 観客動員数発表"
文字列型を使うことで、可読性の高いテキスト情報をデータとして扱うことができ、表示や検索も容易になります。
3.3.2 数値(Number)
数値は整数や浮動小数点数を扱う型で、統計情報や計算値の表現に適しています。JSONでは、小数点を含む値もそのまま指定できます。
例(日本:東京オリンピック観客数)
"attendees": 68000
例(グローバル:国別GDPデータ)
"GDP": 25000.5
数値型を用いることで、統計分析や計算処理、ランキング表示などが正確かつ効率的に行えます。
3.3.3 真偽値(Boolean)
真偽値は、true または false の2値を持つ型で、条件判定や状態管理に用いられます。フラグやスイッチ、オン・オフ情報の表現に最適です。
例(日本:鉄道運行状況)
"operational": true
例(グローバル:イベント参加登録)
"registered": false
真偽値型は、条件分岐や表示制御など、プログラムやAPIでの論理判断に便利です。
3.3.4 null
nullは、値が存在しないことを示す特殊な型です。未設定や未発表の情報を明示的に扱う際に利用されます。
例(日本:映画公開日未定)
"releaseDate": null
例(グローバル:海外プロジェクト期限未設定)
"deadline": null
null型を使うことで、値が空であることを明確に示せるため、データの欠損や未設定状態を管理しやすくなります。
3.3.5 オブジェクト(Object)
JSONオブジェクトは、キーと値のペア で構成され、複雑なデータを階層的に整理できます。オブジェクトを使うことで、APIレスポンスや設定ファイルなど、まとまりのあるデータ管理が容易になります。
例(日本:商品情報)
{
"productId": "JP12345",
"name": "抹茶ラテ",
"price": 450,
"categories": ["飲料", "カフェ"],
"availability": {
"Tokyo": true,
"Osaka": false
}
}
例(グローバル:スポーツ大会結果)
{
"event": "World Cup 2026",
"hostCountry": "Canada",
"teams": {
"Japan": {"rank": 12, "points": 6},
"USA": {"rank": 1, "points": 12}
}
}
オブジェクトを使うことで、複雑な階層データを一つのまとまりとして扱え、参照や更新も簡単に行えます。
3.3.6 配列(Array)
JSON配列は、順序付きの要素集合 で、リストやランキング、多次元データの表現に最適です。順序が保持されるため、ランキングやタイムラインの管理にも適しています。
例(日本:観光地ランキング)
[
{"city": "Tokyo", "visitors": 14000000},
{"city": "Kyoto", "visitors": 5600000},
{"city": "Osaka", "visitors": 8800000}
]
例(グローバル:国際会議参加者)
[
{"name": "Alice", "country": "USA", "attended": true},
{"name": "Yuki", "country": "Japan", "attended": false},
{"name": "Carlos", "country": "Brazil", "attended": true}
]
例(多次元配列:都道府県と主要都市)
[
["Tokyo", ["Shinjuku", "Shibuya", "Minato"]],
["Osaka", ["Kita", "Chuo", "Naniwa"]],
["Kyoto", ["Fushimi", "Sakyo", "Higashiyama"]]
]
配列を活用することで、順序付きデータや複数要素の集合を効率よく管理でき、データ操作や表示も簡単になります。
4. JSON・ XML・ YAMLとの違い
ここでは、JSONと関連技術(XML、YAML)の違いを、多角的な観点から比較し、データ交換や設定管理における位置付けを明確にします。
項目 | JSON | XML | YAML |
定義 | 軽量なテキスト型データ交換形式 | タグ構造を持つマークアップ言語 | 可読性重視の構成記述言語 |
特徴 | シンプル・軽量・階層構造 | 厳密な構文・柔軟性 | 人間が読みやすい記述 |
主な用途 | API、設定、保存形式 | 文書構造、設定 | 設定、インフラ構成 |
データ型対応 | 数値・文字列・配列・オブジェクトなど | 文字列中心、独自型は拡張可能 | 数値・文字列・配列・オブジェクトなど |
パース速度 | 高速(軽量かつ構文が簡単) | 比較的遅い(タグ解析が必要) | 中程度(柔軟だが階層が複雑になると重くなる) |
言語依存性 | ほぼなし(多くの言語で標準サポート) | 言語依存なしだが解析ライブラリが必要 | 言語依存少ないがライブラリが必要 |
コメント対応 | 原則不可 | 可(<!-- -->) | 可(#で記述) |
サポート状況 | Web APIで標準的に使用 | 文書交換や古いシステムで広く使用 | DevOpsや構成管理で人気 |
JSONは軽量で高速、API通信に最適な形式として広く使われる一方、XMLは柔軟で厳密な文書構造の管理に向き、YAMLは可読性の高さから設定ファイルやインフラ構成管理で重宝されます。
これらの違いを理解することで、用途に応じた適切なデータ形式の選択が可能となります。
5. JSONの用途
JSONはデータ交換、設定ファイル、保存形式など多様な用途で利用されます。
5.1 API通信
JSONは、サーバーとクライアント間でデータをやり取りする際に最も一般的な形式です。特にREST APIでは標準フォーマットとして採用され、異なるプラットフォーム間でも互換性が高く、システム間連携が容易になります。
構造がシンプルで解析が高速なため、通信処理の効率化に貢献します。クライアントは軽量にデータを読み込め、サーバーも容易に生成可能です。通信遅延の低減やレスポンス速度向上に役立ちます。
また、JSONは人間にとっても可読性が高く、開発やデバッグ時に内容を直感的に確認できます。エラー発生時もデータの確認が容易で、問題解決の効率が高まります。
さらに、JavaScriptやPythonなど主要な言語でネイティブに扱えるため、フロントエンド・バックエンド両方で統一したデータ処理が可能です。クロスプラットフォーム開発においても標準化された利点を活かせます。
5.2 設定・構成管理
アプリケーションの設定ファイルとしてJSONを利用することは非常に一般的です。階層構造を持つことで、複雑な設定項目を整理し、必要な部分だけを容易に変更できます。
プログラムからの自動読み込みが簡単で、動的な設定変更やバリデーションも容易です。開発・運用フェーズでの柔軟性が高く、環境ごとに異なる設定を簡単に切り替えられます。
チーム開発においても、JSONはバージョン管理システムと相性が良く、変更履歴の追跡や差分確認が容易です。これにより、設定変更の管理が効率化され、トラブルを未然に防げます。
さらに、環境設定ファイルをJSONで統一することで、開発・テスト・本番環境間での整合性を確保できます。標準化された形式での設定管理は、大規模プロジェクトでもメリットが大きいです。
5.3 データ保存形式
JSONは、ログデータや軽量データベースの保存形式としても活用されています。テキストベースで構造が明確なため、保存や転送が容易です。
NoSQLデータベース(MongoDBなど)では、JSONに似た形式(BSON)が採用され、柔軟なスキーマでデータを保存可能です。これにより、複雑なデータ構造を効率的に扱えます。
さらに、JSONファイルはそのままバックアップやアーカイブとして利用でき、簡単なデータ管理手段として非常に便利です。移行や同期も容易で、軽量なストレージ管理が可能です。
また、JSONは他の形式と比べて汎用性が高く、将来的に異なるアプリケーション間で再利用しやすい点も大きな利点です。単純な保存から複雑なデータ連携まで柔軟に対応できます。
5.4 データ解析・可視化
JSONはデータ解析の中間形式としても重宝されます。一度JSONに変換することで、様々な解析ツールやプログラミング言語で容易にデータを扱えます。
PythonやJavaScriptなど主要な言語でネイティブサポートされており、データ抽出、変換、統計処理が簡単に行えます。これにより解析フローの効率化が可能です。
可視化ライブラリにJSONデータを渡すことで、グラフやチャートとして直感的に情報を表現できます。リアルタイムデータのダッシュボード表示にも最適です。
さらに、JSONを標準形式として利用することで、データパイプラインやETL処理との親和性も高くなり、大規模データ解析やBIツールとの連携が容易になります。
5.5 フロントエンド開発での状態管理
フロントエンドアプリケーションでは、JSONが状態管理データ構造として活用されます。ReactやVue.jsでは、サーバーから取得したJSONをそのままコンポーネントに反映できます。
状態管理ライブラリ(Redux、Vuexなど)では、JSON形式のオブジェクトをストアに保存し、必要に応じて変更・更新します。これにより、UIとデータ状態の同期が容易になります。
また、JSONは軽量で扱いやすいため、フロントエンド全体のパフォーマンスに悪影響を与えず、効率的にデータを操作可能です。状態管理の統一性も保たれます。
さらに、JSONを用いた状態管理により、画面遷移やイベント処理におけるデータ整合性を高く保つことができ、開発効率と品質の向上に貢献します。
5.6 モバイルアプリケーションとの連携
モバイルアプリでも、サーバー通信や内部データ保存にJSONが多用されます。軽量テキスト形式のため、通信コストやストレージ消費を抑えられます。
APIから取得したJSONを解析してUIに反映することが容易で、アプリのレスポンス向上に寄与します。また、オフライン時にはJSONファイルをキャッシュとして利用し、データの永続性を確保できます。
さらに、モバイルデバイスの性能が限られていてもJSONは処理が軽く、アプリの動作に負荷をかけずにデータ操作が可能です。
これにより、ネットワーク環境が不安定な状況でも、アプリは安定して動作し、ユーザー体験を損なわない設計が実現できます。
5.7 IoTデバイスとのデータ交換
IoTデバイス間やクラウドサービスとの通信でもJSONは広く利用されます。軽量で構造がシンプルなため、処理能力が限られたデバイスでも扱いやすいです。
センサー情報や制御データをJSONで統一することで、システム全体のデータ統合や管理が容易になります。異なるデバイスやサービス間でも標準化されたフォーマットでデータを扱えます。
また、リアルタイムデータのモニタリングや履歴管理にもJSONは適しており、IoTシステムの効率的な運用を支えます。
さらに、軽量で可読性の高いJSONを活用することで、クラウド連携やエッジ処理との統合もスムーズになり、IoTアプリケーション全体の拡張性や保守性が向上します。
6. JSONの利点
JSONはシンプルかつ汎用性の高いデータ形式で、開発者に多くの利点をもたらします。

6.1 表記が簡潔で理解しやすい
JSONはテキストベースで、人間にも読みやすい表記が可能です。キーと値が明確に対応しているため視認性が高く、構造全体をひと目で把握できます。特にプログラミングに慣れていない人でも直感的に読み解きやすい形式であるため、データ内容の理解がスムーズに進む点が大きな利点です。
この簡潔さにより、開発中のデバッグや設定ファイルの確認が容易になります。余計な記法が少ないためデータの流れを追いやすく、問題箇所の切り分けや値の調整を迅速に行えます。ミスの原因を探す際にも、構造の見通しの良さが大きく役立ち、開発のサイクル全体を効率化します。
複雑なデータ構造でも、ネストされたオブジェクトや配列を用いることで整理して表現可能です。階層的なデータ関係をそのまま書き下せるため、実際のシステム構造やビジネスロジックを反映しやすい点も特徴です。多層的なデータモデルを扱う場面でも、各要素の意味関係が曖昧になりにくく、変更時の影響範囲も追跡しやすくなります。
また、チーム開発においても、JSON形式は他の開発者が理解しやすく、共同作業の効率向上に寄与します。形式そのものが広く普及しているため、エンジニア間での認識ズレが起こりにくく、レビューや引き継ぎもスムーズになります。開発プロセス全体で“共通言語”として扱える点が、組織的な開発を支える強みとなります。
6.2 パース処理が高速
JSONは軽量なデータ形式であり、解析(パース)処理が非常に高速です。データ量が少なく構造もシンプルなため、受け取った情報を効率よく処理でき、余計なオーバーヘッドが発生しません。特にWebアプリケーションやAPI通信では、レスポンスの処理速度向上に直結し、ユーザー体験の向上やサーバー負荷の軽減にも大きく寄与します。
多くのプログラミング言語がネイティブでJSONパースをサポートしており、外部ライブラリなしでも容易に扱えます。言語固有の標準APIだけでシリアライズやデシリアライズが実行できるため、導入コストが低く、既存システムへの組み込みもスムーズです。これにより、開発環境に依存しない柔軟なデータ処理が可能になります。
高速処理により、リアルタイムアプリケーションや大量データのやり取りにも適しており、性能面での利点が大きいです。チャット、ライブ更新、センサー情報のストリーミングなど、即時性が求められる領域でも安定した動作を実現できます。こうしたパフォーマンス特性は、現代の分散アーキテクチャやクラウド環境でも高く評価される要因となっています。
6.3 多様な言語で扱いやすい
JSONは特定のプログラミング言語に依存しない形式です。JavaScript、Python、Java、Goといった主要言語はもちろん、ほぼすべてのモダンな開発環境で標準的にサポートされています。そのため、どの言語を使用していても同じ形式でデータを扱えるため、学習コストや実装時の負担が小さく、プロジェクト全体の統一性も保ちやすくなります。
この言語間の互換性により、異なるシステム間でのデータ交換が容易になります。バックエンドとフロントエンドが異なる言語で実装されていても、共通のフォーマットを介して自然に連携できる点は大きな利点です。特にREST APIやマイクロサービス間通信では、軽量さと扱いやすさからJSONがデファクトスタンダードとなっており、システム構築の柔軟性を高めています。
さらに、ライブラリやフレームワークが豊富であるため、実装の工数を抑えつつ、高品質なデータ処理を行うことが可能です。検証、変換、スキーマ定義などをサポートするツールも整備されており、開発者は基盤部分に煩わされることなく、アプリケーションロジックに集中できます。これにより、安全性と効率性の両立が実現し、プロジェクトの生産性向上にもつながります。
6.4 階層データの表現が容易
JSONはオブジェクトや配列をネストできるため、複雑な階層データも自然に表現できます。ツリー構造やリスト構造を直感的に整理可能です。
これにより、設定情報やAPIレスポンスのような多段階データも扱いやすくなります。プログラム側でのデータ操作も容易で、読み取り・更新の柔軟性が高まります。
また、階層構造を活かすことで、データの意味や関連性を維持したまま情報を整理できます。
7. JSONの課題
利便性の高いJSONですが、標準仕様上の制限や運用上の課題も存在します。
7.1 コメントを標準で扱えない
JSONは標準仕様としてコメントをサポートしていません。そのため、設定ファイルやデータファイルに注釈を書き込むことができません。
開発者はコメントを別途ドキュメント化するか、キー名や値に意味を含める形で対応する必要があります。
コメント不可は人間が読みやすくする工夫を妨げる場合があり、特に大規模プロジェクトでは注意が必要です。
7.2 型情報を細かく表現しにくい
JSONではデータ型が基本的に文字列、数値、配列、オブジェクト、真偽値、nullに限られます。細かい型情報(例えば日付型やバイナリ型)を直接表現することはできません。
そのため、日付やカスタム型を扱う場合は文字列や別形式でエンコードし、解析時に変換する必要があります。
型変換の手間が増えることで、データ処理やバリデーションの負荷がやや高くなる点が課題です。
7.3 スキーマ定義が別途必要になる場合がある
JSONは柔軟な構造を持つ反面、スキーマを明示しないとデータ整合性の保証が難しい場合があります。
特に複雑なAPIや複数システム間でデータ交換する場合、JSON Schemaなどで明確に型や構造を定義する必要があります。
スキーマ管理を怠ると、想定外のデータが混入してエラーやバグを引き起こす可能性があり、運用上の注意点となります。
8. JSONを扱うシステム領域
JSONは軽量で汎用性が高く、さまざまなシステムやアプリケーションで活用されます。ここでは代表的な領域を整理します。
8.1 クラウドAPI
クラウドサービスでは、JSONが標準的なデータ交換フォーマットとして利用されます。REST APIやGraphQL APIでは、サーバーからクライアントへのレスポンスや、クライアントからのリクエストにJSONが使われます。
JSONの階層構造により、複雑なリソース情報やメタデータも効率的にやり取り可能です。異なるプラットフォーム間でも互換性が高く、クラウドサービスの統合や自動化が容易になります。
さらに、JSONは軽量でテキストベースなので、ネットワーク負荷を抑えながら大量のデータを送受信でき、リアルタイム通信やモバイル環境でも有効です。
8.2 Webブラウザ
Webブラウザでは、JSONはフロントエンドとバックエンドのデータ連携に広く使われます。JavaScriptで直接扱えるため、AJAXやFetch APIを用いた非同期通信に最適です。
フロントエンドアプリでは、サーバーから取得したJSONデータをそのまま画面に反映したり、状態管理ライブラリに格納したりすることで、UIの同期や更新が容易になります。
また、JSONはデバッグがしやすく、開発者がブラウザのコンソールで内容を確認できるため、開発効率向上にも寄与します。
8.3 設定管理ツール
JSONはアプリケーションやサービスの設定ファイルとしても広く活用されます。階層構造を持つことで、複雑な設定項目を整理しつつ、読み書きが簡単です。
多くの設定管理ツールやCI/CDパイプラインはJSON形式をサポートしており、自動化された環境構築やデプロイで活用されます。
さらに、バージョン管理システムと組み合わせることで、設定変更の履歴管理やレビューが容易になり、チーム開発にも適しています。
8.4 ログ収集基盤
JSONはログデータの収集・解析においても利用されます。構造化された形式でログを保存することで、検索や集計、モニタリングが容易になります。
ElasticsearchやFluentd、Logstashなどのログ管理ツールは、JSON形式のログを直接解析・可視化できるため、大規模システムの運用効率が向上します。
また、JSONは軽量でテキストベースのため、ネットワーク転送やストレージへの保存が効率的で、リアルタイム分析や異常検知にも適しています。
おわりに
JSONは、構造化データを扱う上で不可欠な形式として確立されており、シンプルな構文と軽量性によって多様な領域で利用されます。階層構造や柔軟な型表現を持つことで、システム間のデータ連携を円滑にし、開発効率の向上に大きく寄与します。解析や処理の負担を抑えながら、信頼性の高いデータ交換を可能にする点も大きな特徴です。
さらに、JSONは利用領域の広さと技術的基盤の安定性が相互に作用することで、長期間にわたり標準的な形式として定着しています。設定ファイルやデータストレージ、Web APIの通信など、さまざまな用途で活用され、システム間の互換性を保つ役割を果たしています。
JSONはシンプルでありながら高機能なデータ形式として、現代のアプリケーション開発やWebサービスの基盤に不可欠な存在となっています。開発者は、効率的なデータ表現と交換を実現する手段として、JSONを適切に活用することが求められます。









