 EN
EN JP
JP KR
KR
LLMの「ハルシネーション(幻覚)」を減らす技術アプローチ
DXの進展に伴い、生成AIは文章作成や顧客対応、データ分析など多くの分野で活用され、業務効率や競争力向上に貢献しています。しかし同時に、「ハルシネーション」と呼ばれる、事実と異なる情報を生成する問題が顕在化しています。
本記事では、ハルシネーションの定義、原因、種類、リスクを整理し、業界別の影響や最新技術による対策も紹介します。企業が生成AIを安全かつ効果的に導入するための実践的な指針を提供します。
1. ハルシネーションとは?
ハルシネーション(Hallucination)とは、生成AIがもっともらしく見えるが事実とは異なる情報や根拠のない内容を生成する現象を指します。歴史的な出来事の日付の誤りや、実在しない人物の情報などがその一例です。AIの出力は流暢で説得力があるため、ユーザーが誤情報に気づきにくく、信頼を置いてしまうリスクがあります。
この現象は特に企業利用において深刻な課題となります。生成AIは出典を示さないことが多く、誤った情報が顧客やステークホルダーに伝われば、ブランド信頼の低下や法的リスクにつながりかねません。正確性が求められるビジネスシーンでは、ハルシネーションの管理と対策が不可欠です。
2. ハルシネーションの原因
ハルシネーションが発生する背景には、主にAIの学習プロセスや使用するデータの問題があります。以下に、主な原因を詳しく解説します。
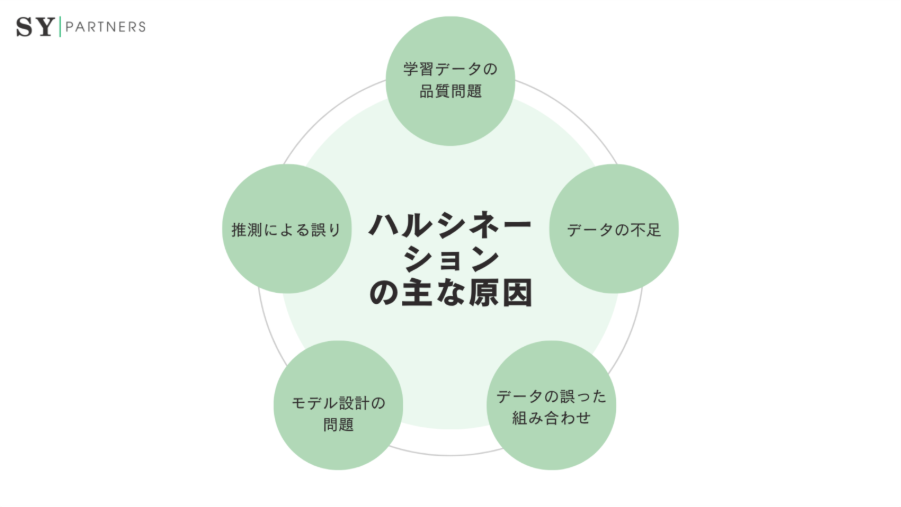
原因 | 説明 |
学習データの品質問題 | 誤った情報や古いデータ、バイアスがかかったデータが含まれる |
データの不足 | 情報が不足し、AIが推測に頼る |
データの誤った組み合わせ | 異なる文脈のデータを誤って統合 |
モデル設計の問題 | アーキテクチャや学習プロセスの欠陥 |
推測による誤り | データの理解不足による不正確な推測 |
2.1 学習データの品質問題
AIが学習に使用するデータに誤りや古い情報が含まれている場合、誤った出力を生成しやすくなります。たとえば、最新の科学的知見が反映されていないデータセットでは、古い情報をもとに回答を導いてしまうことがあります。また、バイアスのあるデータを使うことで、偏った内容が出力されるリスクもあります。
2.2 データの不足
特定の分野やトピックに関する学習データが不十分な場合、AIは限られた知識から推測を行い、誤った回答を生成する傾向があります。例えば、希少疾患に関する情報が少ない場合、AIが誤った診断を行う可能性があります。
2.3 データの誤った組み合わせ
異なる文脈のデータを混同・誤結合して学習した結果、AIが事実とは異なる情報を生成することがあります。関連性のない情報同士を結びつけてしまうことで、不正確な回答が生まれます。
2.4 AIモデルの設計や学習プロセスの問題
AIモデルのアーキテクチャや学習方法に問題がある場合、ハルシネーションの発生リスクが高まります。過剰適合(オーバーフィッティング)や、モデルが過度に複雑である場合、意味の理解が正確に行われず誤出力につながる可能性があります。トレーニング時の検証が不十分だと、誤りがそのまま学習されてしまいます。
2.5 AIの推測による誤り
AIが曖昧な質問や情報が不足しているテーマに対し、推測ベースで回答する際、事実に反する内容を生成することがあります。たとえば、「最新の気候変動対策は?」という問いに対して、十分な情報がないとAIは実在しない政策や技術をでっち上げてしまう可能性があります。
3. ハルシネーションの種類
ハルシネーションは、発生の仕方によって大きく2つのタイプに分類されます。
種類 | 特徴 |
内在的ハルシネーション | 学習データの誤解釈による誤った回答 |
外在的ハルシネーション | 学習データに存在しない情報の創作・捏造 |
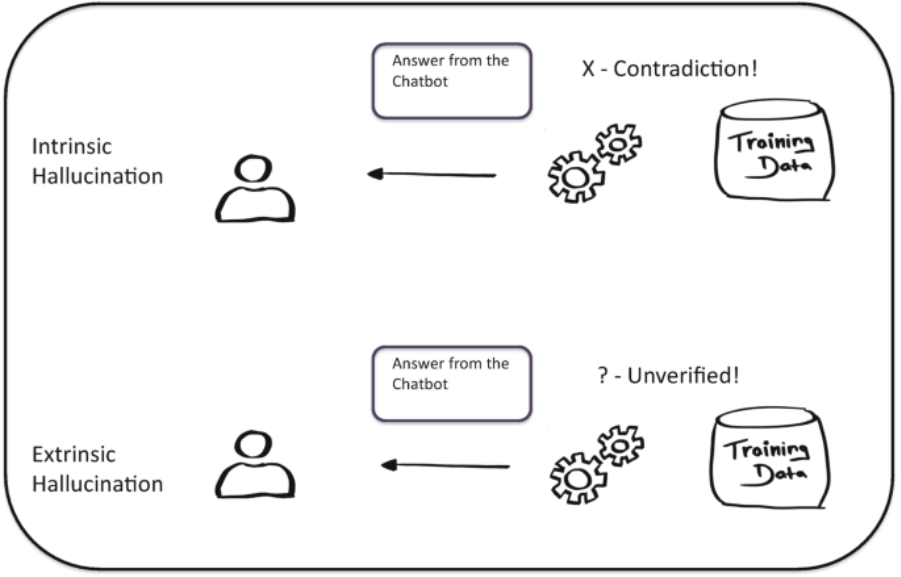
3.1 内在的ハルシネーション(Intrinsic Hallucinations)
内在的ハルシネーションは、学習データに含まれる情報を誤って解釈することで発生します。
たとえば、学習データに「ユーグレナ(ミドリムシ)」の語源が「ラテン語で『美しい目』」とあるにもかかわらず、AIが「ミドリムシの由来はラテン語の美しい目」と誤って生成するケースです。
これは、言い換えや文脈のずれによって生じる比較的軽微な誤りですが、正確性が重視される場面では問題になります。
3.2 外在的ハルシネーション(Extrinsic Hallucinations)
外在的ハルシネーションは、学習データに存在しない情報をAIが創作してしまうケースです。
たとえば、「ミドリムシの名前は『緑が鮮やかで無視できない存在』を意味する」といった、完全に根拠のない情報が生成される場合です。
このタイプは、ユーザーの誤解や誤った意思決定につながるリスクが高く、特に注意が必要です。
4. ハルシネーションがもたらすリスク
生成AIによるハルシネーションは、個人や企業に深刻なリスクをもたらします。以下に主な影響を示します。

4.1 誤情報の拡散
AIが生成した誤った情報が、SNSやレポートを通じて広まることで、誤解や混乱を引き起こします。
たとえば、誤った製品仕様が公開されれば、顧客の信頼を損ない、企業の競争力低下につながる恐れがあります。
4.2 誤った意思決定
ハルシネーションに基づく情報で意思決定すると、戦略ミスや経済的損失が発生します。
例:誤った市場予測に基づく投資 → 損失
誤情報に基づく製品開発 → 市場ニーズとのズレ
4.3 信頼性・ブランドの毀損
生成AIによる誤情報が顧客や取引先に提供された場合、企業の信頼性やブランドイメージが損なわれる可能性があります。
特に、医療・金融などの高リスク業界では、正確性が重要視されるため、この影響は重大です。
例:医療現場で誤った診断が提示される → 患者の安全に影響
5. ハルシネーションを減らすための先端技術
ハルシネーションを抑制するために、さまざまな先進技術が開発されています。以下に主要な3つを紹介します。
技術 | 説明 |
知識グラフ | 事実の構造化により、正確な回答を支援 |
コンテキスト生成制御 | 質問の文脈に忠実な生成を促進し、脱線を防止 |
自動ファクトチェックシステム | 出力をリアルタイム検証し、誤情報を即時検出 |
5.1 知識グラフの活用
知識グラフは、事実やデータの関係を構造化して管理する技術です。これを参照することで、AIは信頼性の高い情報に基づいた回答を生成でき、捏造のリスクを低減できます。
例:医療分野では、疾患と治療法の関係を明確にして誤診を防止。
5.2 コンテキストベースの生成制御
この技術は、AIがユーザーの意図や質問文の文脈を厳密に守るように制御するものです。
例えば「最新データに基づいて回答せよ」と指定することで、古い情報や無関係な推測を防ぐことができます。
5.3 自動ファクトチェックシステム
AIの出力をリアルタイムで検証し、信頼できる情報源と照合することで誤情報を特定する技術です。
特に、ニュース記事生成やチャット対応などで有効とされています。
6. ハルシネーションへの対策

ハルシネーションを最小限に抑えるためには、事前のリスク管理と発生後の対応策の両方が必要です。
対策カテゴリ | 具体策 |
リスク管理 | データ品質向上、グラウンディング、モデル監視、RLHF、プロンプト最適化 |
発生時の対応 | ユーザー教育、ガイドライン策定、ファクトチェック、出力フィルタリング |
6.1 ハルシネーションを防ぐためのリスク管理
学習データの品質向上
高品質で正確なデータセットを用意し、定期的に更新することで、誤った情報や古いデータの影響を軽減します。データのソースを信頼性の高いものに限定することも重要です。
グラウンディング(Grounding)
AIが参照するデータやURLを厳選し、信頼性の高い情報源に限定します。これにより、誤った情報の取り込みを防ぎます。
AIモデルの監視と改善
学習プロセスやモデル設計を定期的に見直し、問題があれば修正します。専門家による継続的な監視が不可欠です。
RLHF(人間からのフィードバックによる強化学習)
人間のフィードバックを活用して、AIの出力精度を向上させます。ユーザーの修正や評価をモデルに反映することで、誤りを減らします。
プロンプトの最適化
曖昧な質問や複雑なプロンプトはハルシネーションを誘発しやすいため、明確で具体的なプロンプトを使用します。例えば、「2023年のデータに基づく」と明示することで、推測を防ぎます。
6.2 ハルシネーション発生時の対応策
ユーザー教育
生成AIの利用者に対し、ハルシネーションのリスクを周知し、回答の真偽を確認する習慣を促します。社内トレーニングやワークショップを通じて、リスク意識を高めます。
ガイドラインの策定
データ品質やプロンプト作成に関する明確なガイドラインを策定し、従業員に配布します。これにより、AIの利用方法を標準化します。
ファクトチェックの徹底
AIの出力を利用する前に、専門家や信頼できる情報源で事実確認を行います。自動化されたファクトチェックツールの導入も有効です。
出力フィルタリング
人間が設計したフィルターを適用し、偏った情報や誤りを検出します。フィルターの基準は、業界や業務内容に応じて設定します。
7. 生成AIを活用するための最適なプラクティス
ハルシネーションは現時点で完全に排除することは難しいため、生成AIを活用する際は、リスクを前提とした戦略が求められます。
7.1 ハルシネーションを前提とした利用
生成AIを導入する企業は、ハルシネーションが発生する可能性を常に考慮し、すべての出力を検証するプロセスを構築する必要があります。特に、重要な意思決定や顧客対応にAIを利用する場合は、ファクトチェックを徹底することが不可欠です。
例えば、AIが生成したレポートを使用する前に、専門家によるレビューを義務付けることが有効です。
7.2 デジタライゼーションとのバランス
生成AIに頼りすぎず、まずは業務のデジタライゼーションを進めることが推奨されます。デジタライゼーションは、正確なデータに基づく業務効率化を可能とし、ハルシネーションのリスクを回避できます。
例えば、データベースの構築や業務プロセスの自動化は、生成AIを導入する前に確立すべき基盤です。これにより、AIを補助的なツールとして活用し、リスクを最小限に抑えることができます。
7.3 生成AIの段階的導入
すべての業務を一気に生成AIに委ねるのではなく、段階的に導入することでリスクを管理します。例えば、生成AIをクリエイティブな提案や補助的なタスクに限定し、重要な意思決定には人間の判断を組み合わせるアプローチが有効です。
段階的導入により、AIの信頼性を評価しながら、徐々に利用範囲を拡大できます。
まとめ
ハルシネーションとは、生成AIが事実と異なる情報や根拠のない内容を生成する現象であり、誤情報の拡散、誤った意思決定、企業信頼性の低下といったリスクをもたらします。主な原因は学習データの品質問題、不足、誤った組み合わせ、モデル設計の欠陥、推測による誤りです。医療、金融、メディアなどの業界では特に深刻で、誤った診断や投資判断、報道の混乱を引き起こす可能性があります。
これを防ぐには、学習データの品質向上、グラウンディング、RLHF、プロンプト最適化、ファクトチェックの徹底が必要です。知識グラフや自動ファクトチェックシステムなどの先端技術も有効です。生成AIを活用する際は、デジタライゼーションを基盤に段階的導入を行い、重要な判断には人間の検証を組み合わせることで、リスクを最小限に抑えつつDXを推進できます。
