 EN
EN JP
JP KR
KR
AIモデルにおける学習率(Learning Rate)の最適化戦略を徹底解説
機械学習や深層学習の学習過程において、モデルの性能を大きく左右する要素の一つが学習率(Learning Rate)です。学習率は、勾配降下法におけるパラメータ更新の「歩幅」を決めるハイパーパラメータであり、値の設定によって学習の収束速度や安定性が劇的に変化します。
学習率が大きすぎると、損失関数の最小値を飛び越えて振動が発生し、学習が不安定になります。一方、小さすぎると収束が遅くなり、十分な最適解に到達できません。適切な学習率を選ぶことは、単に訓練を速めるだけでなく、汎化性能(generalization)を高める上でも重要な要素です。
本記事では、学習率の基本的な役割を確認した上で、主な調整方法と実践的な最適化戦略を体系的に解説します。固定学習率、動的スケジューリング、適応的学習率アルゴリズムなど、モデル特性やデータ構造に合わせた手法を比較しながら、実運用での選択指針を明確にします。
1. 学習率とは?
学習率(Learning Rate)は、機械学習モデルが最適化の各ステップでどの程度パラメータを更新するかを制御するハイパーパラメータです。モデルは損失関数(予測値と実際の値の差を測る指標)を最小化することを目的として繰り返し学習を行いますが、その更新の「一歩の大きさ」を決めるのが学習率です。
学習率が大きすぎると、損失関数の最小値を飛び越えてしまい、学習が発散する可能性があります。逆に、小さすぎると更新がわずかにしか進まず、最適解にたどり着くまでに非常に多くの反復が必要になります。つまり、学習率は学習のスピードと安定性のバランスを取る調整弁として機能します。
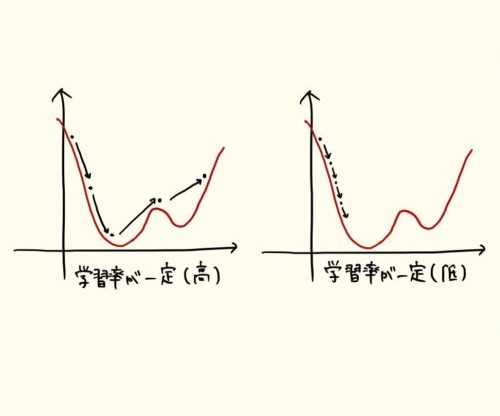
最適な学習率を設定することは、モデルが効率的かつ安定的に収束し、十分な性能を発揮するための鍵となります。学習率の調整は単なる数値設定ではなく、モデルが「どのように学ぶか」を根本から決定する重要な設計要素なのです。
2. 学習率スケジューリングとは?
学習率スケジューリングとは、モデルの訓練過程において学習率(Learning Rate)の値を段階的または動的に変化させる手法を指します。学習率は、勾配降下法などの最適化手順でパラメータを更新する際に、その更新幅を決定する極めて重要な要素です。
学習初期には探索を広げるために大きめの学習率を用い、学習が進むにつれてより安定的な収束を得るために学習率を下げることで、より効率的に最適解へ到達することが可能になります。
3. 学習率スケジューリングの手法(Learning Rate Scheduling)
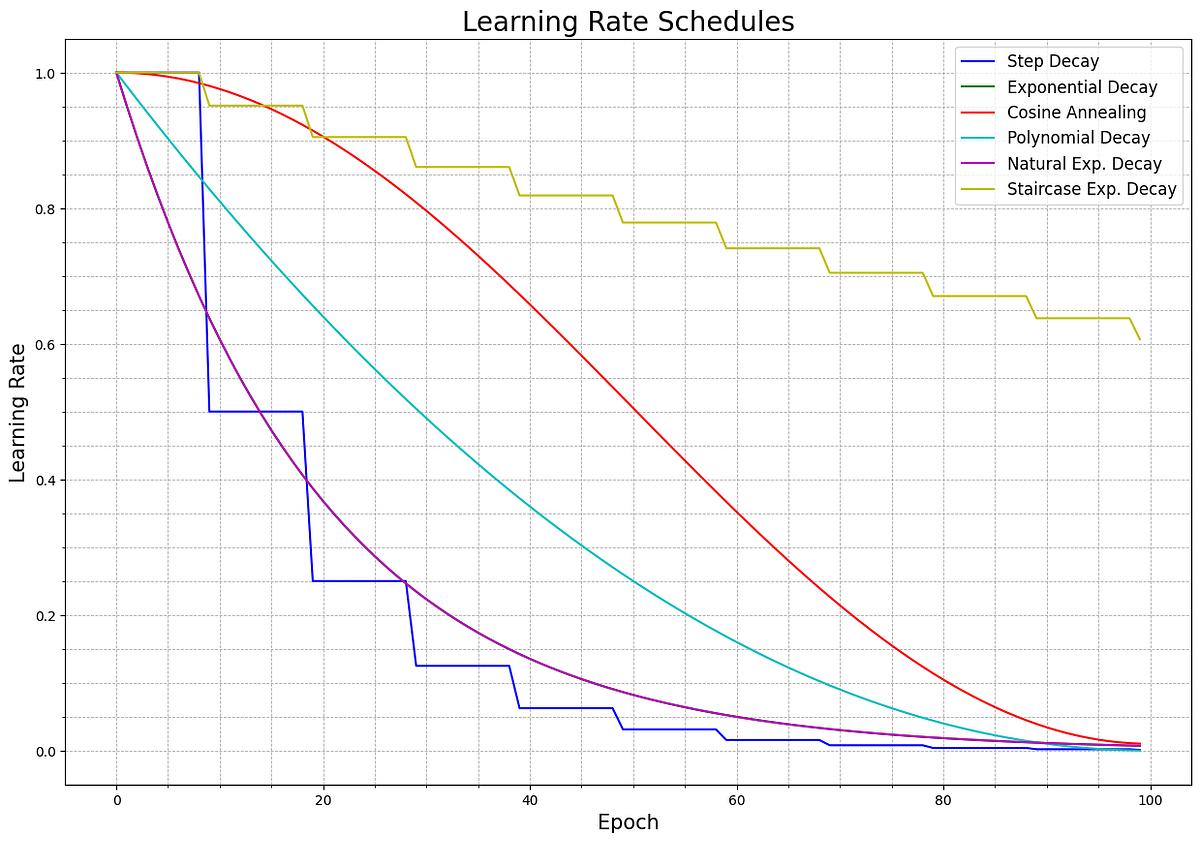
学習率スケジューリングとは、学習の進行状況に応じて学習率(Learning Rate)を動的に調整する手法です。学習初期では高い学習率を設定して広範な探索を行い、後半では学習率を下げて安定した収束を目指します。これにより、訓練の効率化や過学習の防止を実現できます。以下では、代表的な5つの手法について解説します。
3.1 ステップ減少(Step Decay)
ステップ減少は、一定のエポック(学習回数)ごとに学習率を段階的に減少させるシンプルな方法です。例えば、10エポックごとに学習率を0.1倍にする設定が一般的です。初期段階では高い学習率で大まかに最適解を探索し、後半では学習率を下げて微調整を行うことで安定した収束を実現します。
この手法は実装が容易で、学習の安定性を確保しやすいという特徴があります。そのため、CNN(畳み込みニューラルネットワーク)を用いた画像分類や物体検出などのタスクで広く採用されています。
3.2 指数減少(Exponential Decay)
指数減少では、学習率を指数関数的に徐々に減らしていきます。ステップ減少のように急激に変化せず、滑らかに学習率を低下させることで、過学習を抑えつつ安定した収束を促進できます。数式的には、エポック数に応じて学習率を「初期値 × decay_rate^(epoch)」の形で更新します。
長期にわたる訓練や、学習率の急激な変動を避けたいケースに適しています。特に、自然言語処理や音声認識など、連続的かつ大規模なデータを扱うディープラーニングモデルで効果的に機能します。
3.3 コサインアニーリング(Cosine Annealing)
コサインアニーリングは、コサイン関数に基づいて学習率を周期的に変化させる手法です。学習率が徐々に下がり最小値に達した後、再び上昇するというサイクルを繰り返すことで、モデルが局所最小値(ローカルミニマ)に閉じ込められるのを防ぎます。この性質により、探索の再活性化(re-exploration)が可能になります。
特にTransformerモデルやBERT系モデルの訓練で用いられることが多く、再学習の効果を取り入れることで汎化性能を向上させます。滑らかな変動パターンのため、訓練の安定性と精度のバランスが良い点も魅力です。
3.4 学習率ウォームアップ(Warmup)
学習率ウォームアップは、学習初期において学習率を小さな値から徐々に上昇させる手法です。学習の初期段階でモデルの重みが不安定な状態にあるため、いきなり高い学習率を適用すると収束が乱れる場合があります。ウォームアップはこの問題を防ぎ、スムーズな学習立ち上げを実現します。
一定のウォームアップ期間を経た後は、他のスケジューリング手法(例えばコサインアニーリングや指数減少)と組み合わせて使用されます。特に大規模モデルや分散学習では、学習の安定化に不可欠なテクニックとして広く採用されています。
3.5 プラトーでの減少(Reduce on Plateau)
プラトーでの減少は、検証損失(Validation Loss)や精度などの評価指標が一定期間改善しない場合に、自動的に学習率を減少させる手法です。モデルの性能が「停滞状態(Plateau)」に達したときに学習率を下げることで、新たな局所最適解を探索しやすくなります。
この方法は動的かつデータ依存的に学習率を調整できる点が強みです。多くの深層学習フレームワーク(例:PyTorch, TensorFlow)で標準機能として実装されており、実運用環境でのモデル改善にも広く用いられています。
これらの手法は、学習初期の探索段階では大きな学習率を維持し、最終的に安定収束に向けて学習率を下げるという考え方に基づいています。学習が進行するにつれて更新量を微調整することで、より滑らかに最小値へ到達できます。
4. 適応的学習率アルゴリズム
適応的学習率アルゴリズム(Adaptive Learning Rate Algorithm)は、学習の進行状況やパラメータごとの勾配特性に応じて、自動的に学習率を調整する仕組みを持つ最適化手法です。固定の学習率を使用する場合と異なり、勾配の大きさや方向の変化に合わせて更新幅を動的に変化させるため、より効率的で安定した学習を実現します。
この手法は、複雑な損失関数を持つ深層ニューラルネットワークの訓練において特に有効であり、手動での学習率チューニングを大幅に軽減できる点が大きな利点です。以下では、代表的な適応的学習率アルゴリズムの特徴を整理します。
4.1 AdaGrad(Adaptive Gradient)
AdaGradは、各パラメータの更新履歴を考慮して学習率を個別に調整する手法です。頻繁に更新されるパラメータには学習率を小さく、あまり更新されないパラメータには学習率を大きく設定します。これにより、まれに出現する特徴量にも適切に対応できるようになります。
ただし、学習が進むにつれて学習率が過度に減少し、最適化が停滞する傾向がある点が課題です。
4.2 RMSProp(Root Mean Square Propagation)
RMSPropは、AdaGradの学習率減衰問題を改善した手法です。過去の勾配の二乗平均を指数的移動平均として保持し、直近の勾配情報により重み付けを行います。これにより、学習率が極端に小さくならず、オンライン学習や非定常データにも適応できます。
安定した収束を実現する点で、ディープラーニングにおける標準的な選択肢の一つとなっています。
4.3 Adam(Adaptive Moment Estimation)
Adamは、モメンタムとRMSPropの長所を統合した最も広く用いられる最適化手法です。一次モーメント(平均)と二次モーメント(分散)の両方を利用し、勾配の方向と大きさを滑らかに制御します。
学習初期から高速な収束を実現しつつ、局所解への過剰適応を防ぐ効果もあります。さらに、学習率スケジューリングとの併用にも適しており、多くのモデルで標準設定として採用されています。
4.4 AdamW(Weight Decay Regularized Adam)
AdamWは、Adamの改良版として登場したアルゴリズムで、正則化項(Weight Decay)をパラメータ更新とは独立に適用することにより、汎化性能を向上させています。
従来のAdamでは、重み減衰が勾配スケーリングに影響を受けてしまう問題がありましたが、AdamWはこの点を解消し、より一貫した最適化挙動を実現します。大規模モデルの学習や自然言語処理タスクにおいて特に効果的です。
4.5 AdaBelief
AdaBeliefは、Adamの理論的枠組みを継承しつつ、勾配の予測誤差に基づいて学習率を調整する手法です。勾配の変動が小さい場合には学習率を高め、変動が大きい場合には抑えることで、より信頼性の高い更新を行います。
収束の安定性と汎化性能の両立を実現し、過剰学習を抑制する傾向があります。
適応的学習率アルゴリズムは、手動によるパラメータ調整の負担を軽減し、さまざまなタスクにおける最適化性能を大幅に向上させる技術です。特にAdam系アルゴリズムは、計算効率、安定性、汎化力のバランスに優れており、AGIを含む高度なAIシステムの基盤を支える重要な要素となっています。
5. 学習率スケジューリングと他の手法の組み合わせ
学習率スケジューリング(Learning Rate Scheduling)は、ニューラルネットワークの学習を安定させ、最適解への収束を促進するための重要なテクニックです。しかし、単独で使用するよりも、他の学習支援手法と組み合わせることで、より高い汎化性能と学習効率を実現できます。以下では、代表的な5つの併用手法について解説します。
5.1 早期停止との併用
早期停止(Early Stopping)は、学習が進む中で検証誤差が悪化し始めた時点で学習を打ち切ることで、過学習を防ぐ手法です。これを学習率スケジューリングと併用することで、モデルの収束をより効果的にコントロールできます。
具体的には、学習率を徐々に低下させながら損失関数の改善を観察し、改善が止まった段階で早期停止を行うことで、最も汎化性能の高いモデルを得ることが可能です。この組み合わせは、過学習を防ぎつつ計算コストを抑える点でも有効です。
5.2 正則化との併用
正則化(Regularization)は、モデルの複雑さを制御し、過学習を抑制するための基本的な技術です。L1正則化やL2正則化、Dropoutなどの手法を学習率スケジューリングと併用することで、学習の安定性を高めながらパラメータの一般化性能を向上させることができます。
特に、学習率を段階的に減少させるスケジューリングは、正則化の効果を補完し、最終段階でより滑らかな最適化を実現します。これにより、モデルがデータに過度に適応することなく、よりバランスの取れたパラメータ更新が行われます。
5.3 モメンタム最適化との併用
モメンタム最適化(Momentum Optimization)は、勾配の履歴を考慮して更新方向を滑らかにする手法です。学習率スケジューリングと組み合わせることで、収束の速さと安定性を両立できます。
初期段階では高い学習率と強いモメンタムで探索を広げ、後半では学習率を下げて微調整を行うことで、局所解からの脱出と精密な最適化を同時に実現します。この組み合わせは、特に深層ネットワークでの訓練において効果的です。
5.4 バッチ正規化との併用
バッチ正規化(Batch Normalization)は、各層の出力を正規化して勾配消失や爆発を抑制する手法です。これと学習率スケジューリングを併用することで、学習率を高めに設定しても安定した学習が可能になります。
また、スケジューリングによって学習率を徐々に低下させることで、後半の学習における振動を抑え、よりスムーズな収束を実現します。結果として、トレーニング速度と精度の両立が図られます。
5.5 データ拡張との併用
データ拡張(Data Augmentation)は、学習データを変形・回転・ノイズ付与などによって人工的に増やし、モデルの汎化性能を高める技術です。学習率スケジューリングと併用することで、多様なデータに対しても安定して収束する学習プロセスを構築できます。
特に、スケジューリングにより学習初期の探索を広げつつ、後半で微調整を行うことで、拡張データに対する過適応を防ぎながら高精度な分類・予測を実現します。
学習率スケジューリングは、単独での利用よりも他の学習最適化技術と組み合わせることで、より強力な効果を発揮します。モデルの安定性、収束速度、汎化性能のバランスを取るためには、データ特性やタスク目的に応じた戦略的な組み合わせが重要となります。
おわりに
学習率は、AIモデルの学習効率と性能を決定づける中核的パラメータです。設定が適切であれば、少ないエポックで高精度のモデルを得ることができますが、不適切であれば、どんな高性能モデルでも性能が発揮されません。
学習率調整の本質は、安定性と柔軟性の両立にあります。固定設定・スケジューリング・適応的最適化などの手法を理解し、タスクやデータ特性に合わせて組み合わせることで、学習過程の最適化が可能になります。
AI開発において、学習率の扱い方は単なるパラメータ調整ではなく、モデル設計そのものの戦略です。本記事の内容を基礎として、より高効率で信頼性の高い学習プロセスを構築していくことが、実務における成功の鍵となるでしょう。
学習率の初期値は、モデルの構造やデータスケールによって最適値が異なります。一般的な勾配降下法では、0.01 前後 が出発点として適していますが、活性化関数や損失関数のスケールによって調整が必要です。
小さすぎると学習が遅くなり、大きすぎると発散するため、まずは広い範囲(例:0.1〜1e-5)で学習率を段階的に試し、損失の減少傾向を観察することが有効です。特にディープネットワークでは、初期段階での損失変化を確認しながら段階的に最適値を探るのが現実的です。
スケジューリングは、損失の改善が緩やかになった段階 で導入するのが効果的です。学習初期は探索を重視して大きな学習率を使用し、学習が進むにつれて徐々に減少させることで、より精密な最適化が可能になります。
また、一定エポックごとに減衰させる「ステップ減少」や、訓練データの変動が大きい場合に用いる「プラトー減少」など、タスクの性質に合わせてタイミングを設計することが重要です。
完全に不要ではありません。適応的学習率アルゴリズムは、勾配の大きさに応じて各パラメータの更新幅を自動で調整しますが、全体的な学習率 は依然として学習の安定性に影響します。
実務では、初期段階で高めの学習率を設定し、訓練の後半に向けてスケジューリングで減衰させる方法がよく使われます。これにより、初期の探索と最終的な収束のバランスを取ることができます。
学習率が高すぎる場合、モデルはパラメータを大きく更新するため、損失が安定せず過学習を誘発することがあります。逆に、学習率が小さすぎると、損失の減少が遅くなり、訓練データに過度に適応してしまう傾向があります。
このため、学習率の変化を緩やかにしながら調整 することで、汎化性能を保ちながら収束を安定させることができます。スケジューリングや早期停止を併用するのが一般的な対策です。
自動調整機能は便利ですが、評価指標の選び方と減少条件の設定 に注意が必要です。
例えば、検証損失を監視する場合、ノイズによる一時的な悪化で学習率が早期に下がってしまうことがあります。そのため、「patience(忍耐期間)」を設定し、一定のエポック改善が見られなかった場合のみ学習率を下げるようにするのが望ましいです。
また、調整幅(factor)の設定も重要で、極端に小さくすると収束が遅れ、過大にすると発散のリスクが高まります。
