 EN
EN JP
JP KR
KR
データセットとは?機械学習での役割・種類・作成方法をわかりやすく解説
データセットは、機械学習や人工知能の発展において欠かせない基盤の一つである。どれほど優れたアルゴリズムを用いても、質の低いデータを扱えば精度は上がらない。したがって、データセットの構成・種類・作成手順・注意点を正しく理解することが、機械学習の成功を左右する重要な要素となる。
本記事では、まずデータセットの定義から出発し、代表的な種類とその特徴、作成の流れ、注意すべきポイントまでを体系的に解説する。単なる用語説明にとどまらず、実務的な視点から、どのようにデータセットを構築・管理すべきかを整理することを目的とする。
また、データセットに関連する概念として「トレーニングデータ」「テストデータ」「バリデーションデータ」などが存在する。これらの違いを理解し、適切に扱うことが精度向上の鍵を握るため、その関係についても詳細に触れていく。
1. データセットとは?
データセットとは、機械学習モデルの訓練・評価・検証に使用されるデータの集合を指します。単一の情報ではなく、特定の目的に沿って整理された多数のデータ点(例:画像、テキスト、数値データなど)で構成されます。これらのデータは、アルゴリズムが学習するための「材料」として扱われます。
データセットは単なる情報の集まりではなく、適切な構造・ラベル付け・フォーマットを備えたものとして設計される必要があります。これにより、モデルがパターンや傾向を正確に学習し、未知のデータに対しても妥当な推論を行えるようになります。
データセットの公開・共有と倫理的配慮
データセットを共有する際には、プライバシー・著作権・機密情報の保護が不可欠である。特に個人情報を含む場合は、匿名化処理やアクセス制限を施すことが求められる。また、公開時にはライセンス条件を明記し、使用範囲を明確に定義することが望ましい。
学術研究や産業応用の場では、こうした倫理的配慮を欠くと、法的・社会的な問題を引き起こすリスクがある。そのため、透明性と責任をもった運用が求められる。
2. トトレーニングデータ・テストデータ・バリデーションデータの違い
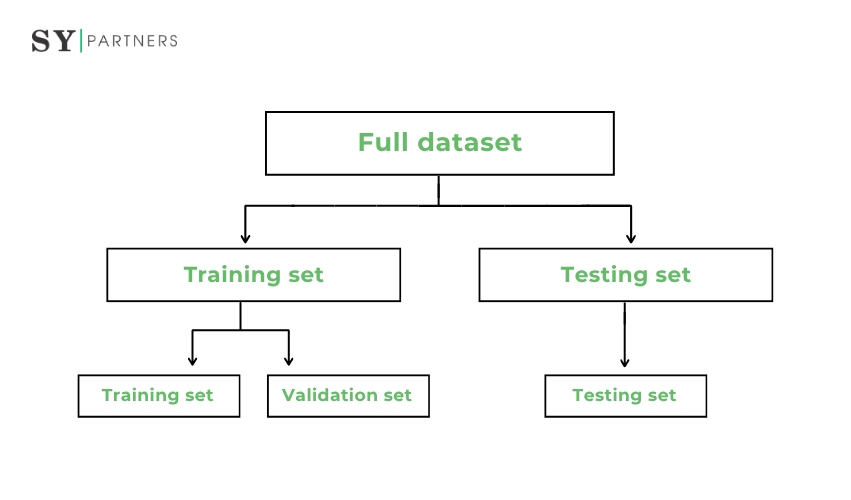
機械学習においては、データを「トレーニングデータ」「バリデーションデータ」「テストデータ」に分けて扱うことが基本となります。
これらはそれぞれ異なる目的と役割を持ち、適切に区別して運用することで、モデルの信頼性と汎化性能を高めることができます。以下に三者の主な違いを整理します。
項目 | トレーニングデータ | バリデーションデータ | テストデータ |
| 主な役割 | 学習の基礎 | 調整・検証 | 性能評価 |
| 利用目的 | モデル構築 | ハイパーパラメータ調整 | 最終テスト |
| データ特徴 | 最も多い・学習用 | トレーニングと同分布 | 未知データ |
| 注意点 | 過学習に注意 | 重複禁止 | 事前利用禁止 |
| 評価段階 | 学習段階 | 調整段階 | 最終評価段階 |
| 使用タイミング | モデル訓練中 | 学習途中で評価 | 学習完了後 |
| データ更新 | 必要に応じて再学習に利用 | モデル改善に反映 | 固定して使用 |
| 出力の用途 | 重み・パラメータ更新 | モデル選択・改善判断 | 精度・再現率などの最終評価 |
これらのデータを明確に区別して使用することは、機械学習モデルの信頼性と再現性を確保するうえで不可欠です。
特に、バリデーションデータとテストデータを混同すると、モデルの評価結果が過大評価されるおそれがあります。
3. 機械学習におけるデータセットの種類
機械学習におけるデータセットは、モデルの学習・検証・評価という異なる段階でそれぞれ特有の役割を持っています。どの段階においても、データの質と構成が精度や汎化性能に大きく影響します。ここでは、代表的な3種類のデータセットについて詳しく解説します。
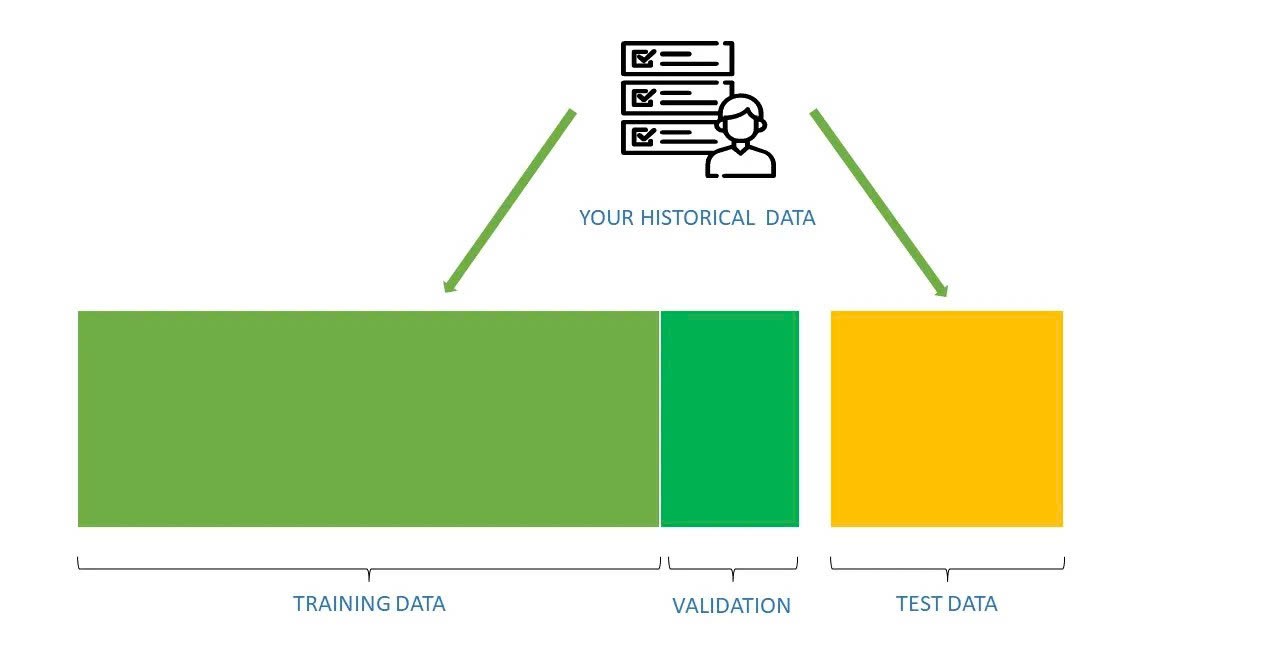
3.1 トレーニングデータ(Training Data)
トレーニングデータは、モデルが学習を行う際の基礎となるデータです。モデルはこのデータを用いて入力と出力の関係を学び、内部パラメータを最適化します。言い換えれば、トレーニングデータは機械学習の「教材」として機能します。
項目 | 内容 |
| 定義 | モデルの学習に使用される主要なデータセットです。 |
| 目的 | 入力データから特徴を抽出し、出力を予測するためのパターンを学習させます。 |
| 使用タイミング | 学習段階(モデル構築時)に使用します。 |
| 特徴 | データ量が多いほど精度が安定しやすく、分布の多様性が求められます。 |
| 課題 | データの偏りやノイズがモデル性能を低下させる可能性があります。 |
| 代表的な利用例 | 画像認識、音声認識、自然言語処理の学習工程など。 |
トレーニングデータの品質が低いと、モデルは誤ったパターンを学習してしまうことがあります。そのため、データの前処理やクリーニングを徹底することが重要です。
また、十分なサンプル数を確保することで、モデルの汎化性能を高めることができます。
3.2 バリデーションデータ(Validation Data)
バリデーションデータは、モデルの汎化性能を確認し、ハイパーパラメータの調整を行うために使用されます。トレーニングデータとは別に用意され、モデルが未知のデータに対してどの程度適切に予測できるかを確認する役割を持ちます。
項目 | 内容 |
| 定義 | モデルの性能を評価し、チューニングを行うためのデータです。 |
| 目的 | ハイパーパラメータの最適化や過学習の検出を行います。 |
| 使用タイミング | 学習過程の途中(モデル調整段階)で使用します。 |
| 特徴 | トレーニングデータと重複しないデータで構成されます。 |
| 課題 | 分割比率が不適切だと検証結果が安定しません。 |
| 代表的な利用例 | ニューラルネットワークの層数・学習率の最適化など。 |
バリデーションデータを使用することで、モデルの調整を客観的に行うことができます。
特にディープラーニングでは、パラメータの数が多いため、適切なバリデーション戦略を取ることが不可欠です。クロスバリデーションなどの手法を取り入れることで、より正確な性能評価が可能になります。
3.3 テストデータ(Test Data)
テストデータは、学習を終えたモデルの最終的な性能を評価するために使用されるデータです。トレーニングおよびバリデーションデータと完全に分離して用意することが原則であり、モデルの汎化能力を客観的に判断する役割を果たします。
項目 | 内容 |
| 定義 | 学習済みモデルの最終性能を確認するための評価用データです。 |
| 目的 | モデルが未知のデータに対してどの程度の精度で予測できるかを検証します。 |
| 使用タイミング | 学習完了後の最終評価段階で使用します。 |
| 特徴 | 現実環境に近い条件のデータを用いることで、実運用時の精度を想定できます。 |
| 課題 | テストデータが訓練データと似すぎている場合、過大評価につながる可能性があります。 |
| 代表的な利用例 | AIモデルの精度検証、アルゴリズム比較、リリース前評価など。 |
テストデータは、モデルが本当に「未知のデータ」に対応できるかを確認するための最終関門です。
ここでの結果は、実際の運用における信頼性を左右します。したがって、テストデータの構成と品質管理は極めて重要です。
各データセットの関係性
3種類のデータセットはそれぞれ独立した役割を持ちますが、全体として密接に関連しています。トレーニングデータで学習した知識を、バリデーションデータで調整し、最終的にテストデータで検証するという流れが、機械学習の基本的なプロセスです。
バリデーションデータを省略すると、モデルがトレーニングデータに過剰に適応してしまう「過学習」が発生しやすくなります。その結果、実運用での精度が著しく低下するおそれがあります。したがって、3種類のデータセットを明確に分け、適切な比率で運用することが不可欠です。
3.4 その他のデータセット分類
データセットは、利用目的だけでなく構造的な観点からも分類することができます。特に、「構造化データ」と「非構造化データ」は、データ解析の方法やアルゴリズム選択に大きく影響します。
項目 | 構造化データ | 非構造化データ |
| 形式 | 表形式(行・列)で整理されたデータです。 | 一定の形式を持たない自由形式のデータです。 |
| 内容の例 | 顧客情報、売上記録、数値・カテゴリデータなど。 | 画像、音声、テキスト、SNS投稿など。 |
| 解析のしやすさ | 数値化されているため統計解析に適しています。 | 特徴抽出や前処理が必要で解析が複雑です。 |
| 活用分野 | 予測分析、業務データ解析、BIツールなど。 | 画像認識、自然言語処理、音声解析など。 |
| 課題 | フォーマット依存性が高く、柔軟性に欠けます。 | 処理コストが高く、大量の計算資源を要します。 |
構造化データは既に整備された形式を持つため、処理が比較的容易です。一方、非構造化データは情報量が多く、前処理や特徴量設計の工夫が必要です。どの種類のデータを扱うかによって、最適なアルゴリズムや学習方法も大きく変わります。
4. データセットの準備方法と作り方
AIモデルの性能を左右する最も重要な要素のひとつが「データセット」です。どれほど高度なアルゴリズムを用いても、学習に使うデータの質が低ければ、正確な結果を得ることはできません。そのため、目的に適したデータをどのように入手・構築するかが、AI開発の成否を決定づける鍵となります。
ここでは、データセットを準備するための代表的な方法と、自社でデータセットを作成する際の具体的な手順について解説します。
4.1 データセットの準備方法
データセットを用意する際には、目的やリソース、コストなどの条件に応じて最適な取得手段を選ぶことが重要です。一般的には、既存のオープンデータを活用する方法から、外部業者への委託、自社独自の構築まで、さまざまな手段が存在します。
以下では、それぞれの方法の特徴と注意点を詳しく見ていきます。
4.1.1 オープンデータの活用
政府機関、大学、企業などが無償で公開しているオープンデータセットを利用する方法です。代表的な例として、画像認識で用いられるImageNetや、自然言語処理で使用されるWikipediaコーパスなどがあります。
これらはコストを抑えながら学習データを確保できる点が大きな利点です。ただし、必ずしも自社の目的や利用条件に一致するとは限らないため、データの内容・構成・ライセンス条件を確認し、適切に利用することが求められます。
4.1.2 データセットの購入
専門企業が販売しているアノテーション済みのデータセットを購入する方法です。特に医療、製造、音声認識などの分野では、高品質なデータを短期間で入手できる点が大きな魅力です。
自社でデータを収集・整理する手間を省ける反面、コストが発生するため、データの品質、出所、ライセンス範囲を明確に確認したうえで導入することが重要です。信頼性の高い販売元を選定することが、後の運用リスクを防ぐうえで不可欠です。
4.1.3 外注による作成
データ収集やアノテーションを専門業者に委託する方法です。自社内で十分なリソースを確保できない場合や、大規模データを扱うプロジェクトでは有効な手段となります。
外注先を選定する際は、品質管理体制、納品フォーマット、セキュリティ対策、スケジュールなどを事前に明確化する必要があります。委託後も定期的な進捗確認やサンプル検証を行い、品質の一貫性を確保することが望まれます。
4.1.4 自社で作成
自社でデータセットを構築する方法は、最も柔軟性が高く、目的に最も適した内容に調整できる手段です。社内に蓄積された顧客情報、ログデータ、アンケート結果などを活用し、必要に応じて新しいデータを収集します。
この方法は時間と労力を要しますが、独自の業務内容や分析目的に最適化されたデータセットを構築できるという大きな利点があります。次の節では、この「自社作成」の手順を段階的に説明します。
4.2 自社でのデータセット作成手順
自社でデータセットを構築する場合、目的の設定からデータ分割まで、一連の工程を計画的に進めることが求められます。特に、自社特有の業務データや顧客情報を扱う際には、品質と法的遵守の両立が不可欠です。
以下では、データセット作成のプロセスを段階的に整理し、実務でのポイントを解説します。
4.2.1 目的の明確化
最初に、AIモデルの開発目的を明確に設定します。どのような課題を解決したいのか、どのような結果を導き出したいのかを具体的に定義することが重要です。目的が不明確なままデータ収集を始めると、不要な情報が混在し、後の工程で修正が必要になる可能性があります。
そのため、まずは「目的」「対象範囲」「評価基準」を明文化し、関係者間で共有しておくことが望ましいです。
4.2.2 データ収集
次に、定義した目的に基づき必要なデータを洗い出し、収集を行います。社内データベースや業務ログ、アンケート結果などの既存データを活用するほか、外部ソースから新たに取得する場合もあります。外部データを利用する際には、著作権や個人情報保護法などの法的要件を遵守することが不可欠です。
また、偏りを防ぐために複数のデータソースを組み合わせ、多様性のあるデータを確保することが望まれます。
4.2.3 アノテーション
収集したデータに対してラベル付け(アノテーション)を行います。画像データの場合は「犬」「猫」といったカテゴリを付与し、テキストデータでは感情分類や固有表現のタグ付けを行います。
アノテーションの精度はモデルの性能に直結するため、作業ルールを統一し、複数人による確認体制を設けることが重要です。特に曖昧な判断を避け、客観的かつ再現性の高い基準を維持することが求められます。
4.2.4 データ加工
アノテーションが完了したデータは、そのままではモデルに入力できない場合が多いため、前処理を行います。欠損値の補完、異常値の除去、スケーリングや正規化などの工程を経て、学習に適した形式に整えます。画像データであればサイズや解像度の統一、テキストであればノイズ除去やトークン化などを実施します。
これらの加工は、学習効率を高め、誤差を減らすための不可欠な工程となります。
4.2.5 データ分割
最後に、整備されたデータをトレーニングデータ、バリデーションデータ、テストデータに分割します。一般的な比率は8:1:1とされますが、データの性質や量によって調整することもあります。偏りを防ぐためにランダム分割や層化抽出を用いることが推奨されます。
適切な分割を行うことで、過学習を防ぎ、実運用におけるモデルの汎用性と信頼性を高めることができます。
5. データセットを扱う際の注意点

データセットを活用する際には、単に大量の情報を集めるだけでなく、「品質」「構造」「公平性」など、さまざまな観点から注意を払う必要があります。
以下では、データセットを取り扱う上で特に重要となるポイントを整理します。
5.1 バイアスと偏り
データセットに含まれる偏りは、モデルの出力結果に直接影響します。特定の属性に偏ったデータで学習した場合、その偏向が出力にも再現されてしまいます。特に倫理的・社会的影響を伴う分野では、公平性を確保するためのデータ設計が欠かせません。
5.2 ラベル付けの品質
教師あり学習ではラベルの正確さが精度に直結します。誤ったラベルが混入すると、モデルが誤学習を起こすため、専門知識を持つ人間によるチェック体制が必要です。
5.3 データの更新と管理
データセットは固定的なものではなく、時間の経過とともに特性が変化します。したがって、定期的な更新とバージョン管理が求められます。新しい情報を反映しつつ、過去のデータとの整合性を維持することで、モデルの信頼性を長期的に保つことができます。
5.4 データの前処理とクレンジング
収集したデータには欠損値、重複、外れ値などが含まれる場合があります。これらを適切に処理しないと、学習結果が不安定になったり、誤った傾向を学習してしまうおそれがあります。そのため、正規化・標準化・欠損補完などの前処理を丁寧に行うことが重要です。
5.5 プライバシーとセキュリティ
個人情報や機密情報を含むデータを扱う際は、プライバシー保護の観点から匿名化や暗号化が不可欠です。また、データへの不正アクセスや漏洩を防ぐためのセキュリティ対策も同様に重要です。
5.6 データの多様性と代表性
モデルの汎用性を高めるためには、特定の地域・年齢・性別などに偏らない多様なデータを確保する必要があります。多様性の低いデータで学習すると、特定の条件下でのみ高精度に動作し、他のケースでは誤判定を起こすリスクが高まります。
6. 高品質なデータセットを構築するためのポイント
高性能な機械学習モデルを実現するためには、単にデータ量を増やすだけでは不十分です。データセットの「質」を高めることが、モデルの信頼性・汎用性・再現性を左右します。
以下では、高品質なデータセットを構築するために考慮すべき主な要素を整理します。
6.1 網羅性
対象領域を十分にカバーしていることが重要です。特定の条件や属性に偏らず、多様なデータを含めることで、モデルが幅広いケースに対応できるようになります。
6.2 一貫性
同一の基準・形式でデータが整備されていることが求められます。フォーマットや単位、ラベル付けの基準が統一されていないと、学習過程で誤認識や精度低下を招くおそれがあります。
6.3 再現性
同じ条件で再度データを収集した際に、同様の結果が得られることが理想です。再現性の確保は、モデルの検証や他の研究者による再利用を容易にし、研究の信頼性を高めます。
6.4 透明性
データの出所、収集方法、処理過程、ラベル付け基準などが明示されている必要があります。透明性の高いデータは、信頼性を担保し、外部監査や説明責任にも対応しやすくなります。
6.5 最新性
社会や環境の変化に対応するためには、データが最新の状態に保たれていることが重要です。古いデータに依存すると、現実との乖離が生じ、モデルの精度が低下する可能性があります。
6.6 バランス
カテゴリ間のデータ数や属性分布に偏りがないようにすることも大切です。極端に不均衡なデータは、モデルが特定クラスに過剰適応する原因となります。サンプリングやデータ拡張などの手法を活用して、バランスを最適化する必要があります。
6.7 メタデータの整備
データそのものだけでなく、収集日時、使用機器、処理履歴などのメタデータを適切に管理することで、分析の再現性やトレーサビリティを確保できます。特に大規模データでは、メタデータ管理が品質維持の鍵となります。
これらの要素を総合的に満たすことで、学習アルゴリズムの性能を最大限に引き出し、長期的に信頼できるデータ資産として活用することが可能になります。
おわりに
データセットは機械学習の基盤であり、その品質が最終的な成果を左右します。どれほど優れたアルゴリズムを用いても、データの質が低ければ高精度な結果は得られません。そのため、定義・種類・作成手順・注意点を正しく理解し、収集から管理までを一貫した方針で行うことが重要です。体系的に整備されたデータセットは、学習の安定性と再現性を高め、信頼性の高いモデル構築につながります。
また、データの偏りを抑え、倫理的に適切な取り扱いを徹底することも欠かせません。公平性やプライバシー保護を意識したデータ設計を行うことで、社会的に信頼されるAI開発が可能になります。高品質なデータセットの整備は単なる準備ではなく、モデル性能と信頼性を支える戦略的プロセスといえます。
よくある質問
どちらも不可欠な要素ですが、目的によって優先度が異なります。
たとえば、汎用モデル(例:音声認識、画像分類など)を構築する場合は、多様性を重視すべきです。多様な環境・話者・照明条件などを含むデータを用いることで、現実世界の変動に強いモデルを得ることができます。
一方、専門領域モデル(例:医療診断AI、製造ライン検知AIなど)では、一貫性がより重要になります。撮影角度・解像度・ラベル付けルールが統一されていないと、微細な特徴を正確に学習できず、誤検出や誤分類の原因になります。
理想は、「多様だが一貫している」データを設計することです。つまり、さまざまな条件をカバーしながらも、収集方法・前処理・アノテーション基準を統一することが品質の鍵になります。
外注先に依頼する場合、単に納品されたデータ量ではなく、品質評価指標(Quality Metrics)を設定することが重要です。代表的な基準としては以下のようなものがあります:
・アノテーション精度(Annotation Accuracy):専門家によるサンプリングチェックを行い、ラベル付けの正確率(例:95%以上)を定量的に測定する。
・一貫性(Consistency Rate):複数のアノテーター間で同一データに対する判断が一致する割合を確認する(例:コーエンのκ係数)。
・欠損・重複率:納品データの中に欠損値や重複データがどの程度含まれているかを定期的に監査する。
・メタデータ完全性:収集日時・機材・加工履歴などの記録が適切に付与されているかを確認する。
さらに、初回納品前に「サンプル検証(Pilot Validation)」を実施し、ラベル定義や出力形式の妥当性を確認することで、後工程の手戻りを防げます。
精度低下の原因を切り分けるには、データ主導の検証プロセスが有効です。以下のステップを踏むと判断しやすくなります。
1. データスプリットの再確認:トレーニング・バリデーション・テストデータの分割比率が適切か、重複がないかを検証。
2. データシャッフルテスト:入力データとラベルの対応関係を意図的に崩して学習させ、精度が大幅に下がらなければ、アルゴリズムに問題がある可能性が高い。
3. エラーパターン解析:誤分類されたデータを可視化し、特定カテゴリや条件に偏りがあるかを確認。偏りがあれば、データ側の問題。
4. 学習曲線の観察:トレーニング精度とバリデーション精度の差(ギャップ)が大きければ過学習=データ不足または不均衡、両者が低ければモデル設計や特徴抽出の問題。
データ品質・モデル設計・ハイパーパラメータを分離して検証することで、改善の方向性を明確にできます。
データセットの公開・共有には、法的リスクと倫理的リスクの両面があります。特に注意すべきポイントは次のとおりです。
・著作権(Copyright):他者が作成した画像・文章・音声などを含む場合、著作権者の許諾なしに再配布することは違法。ライセンス条項(例:CC BY、CC BY-SAなど)を確認し、明記すること。
・個人情報保護(Privacy):個人が特定可能なデータ(顔画像、位置情報、音声など)は、匿名化・モザイク化・音声加工などの処理を行う必要がある。
・利用範囲(Usage Scope):データの使用目的(研究目的のみ、商用利用可など)をライセンス文書で明確に定義する。
・倫理審査(Ethical Review):特に人間行動・医療関連データを扱う場合、倫理委員会やIRB(Institutional Review Board)の承認を得ることが推奨される。
また、利用者側にも再配布時の責任(Attribution・Redistribution Policy)を求めることで、データの誤用や不正利用を防止できます。法的遵守だけでなく、「社会的責任」を明示することが信頼されるデータ公開の基本です。








