 EN
EN JP
JP KR
KR
強化学習とは?種類・応用・機械学習との違いまで徹底解説
強化学習(Reinforcement Learning)は、人工知能(AI)や機械学習の中でも特に注目される分野の一つであり、エージェントと呼ばれる学習者が環境との相互作用を通じて最適な行動を見つけ出す仕組みです。ロボットの動作制御、自動運転、ゲームAI、金融取引アルゴリズムなど、多岐にわたる分野で応用が進められています。
強化学習の魅力は、人間のように「試して学ぶ」プロセスを数理的にモデル化できる点にあります。これにより、膨大なデータを事前に与える必要がなく、環境とのインタラクションを通じて自律的に最適化を進めることが可能です。
本記事では、強化学習の基本的な概念から、仕組み、主要な手法、実際の応用例、さらに教師あり学習や教師なし学習との違いまで、体系的に解説します。
1. 強化学習とは?
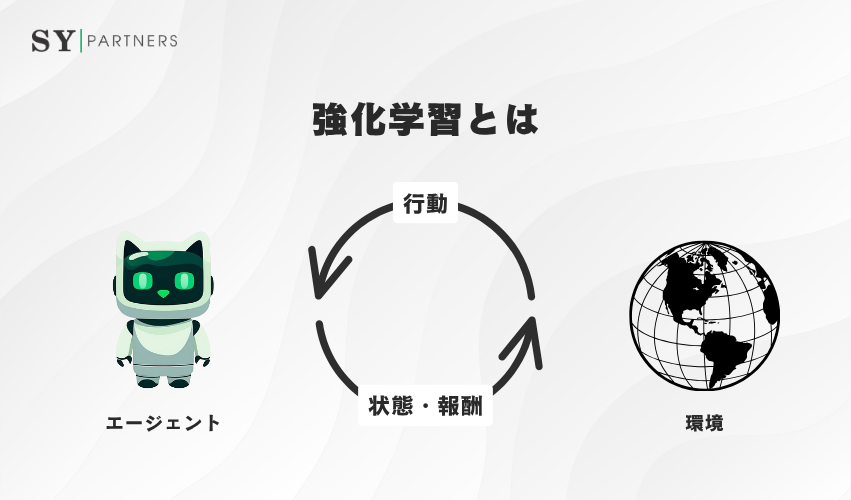
強化学習とは、エージェントが「環境」から報酬(Reward)を得ながら、より良い行動(Action)を選択していくことで、長期的な報酬を最大化する学習方法を指します。つまり、「どのような行動を取れば最も良い結果を得られるか」を学ぶ過程です。
この学習では、教師データや明確な答えは与えられず、エージェント自身が環境から得られるフィードバックをもとに判断を更新します。試行錯誤を繰り返しながら、報酬を最大化する戦略(Policy)を学び取る点が特徴です。
2. 強化学習と機械学習との違い
強化学習は、機械学習の主要な分野の一つであり、「教師あり学習」「教師なし学習」と並んでAIの学習手法を構成する重要な柱です。これら3つの手法は共通して「データから学習する」ことを目的としていますが、学び方と目的の焦点が異なります。以下の表は、それぞれの特徴を比較したものです。
観点 | 教師あり学習 | 教師なし学習 | 強化学習 |
| 学習の目的 | 入力データと正解ラベルの関係を学ぶ | データの潜在構造やパターンを抽出 | 環境との相互作用を通じて報酬を最大化 |
| 入力データ | 正解付きデータ | 正解なしのデータ | 状態・行動・報酬の履歴 |
| 出力 | 予測結果(分類・回帰など) | クラスタリング・次元削減結果など | 最適な行動方針(Policy) |
| 学習プロセス | 正解との誤差を最小化 | データの構造をモデル化 | 試行錯誤を繰り返して行動を改善 |
| 評価基準 | 精度・誤差率 | 分類の妥当性・特徴の抽出度 | 累積報酬(Total Reward) |
| 代表的手法 | 線形回帰、SVM、ニューラルネットワーク | PCA、クラスタリング、オートエンコーダ | Q-learning、DQN、Policy Gradient |
この比較から、強化学習は単なる「データ分析」ではなく「行動最適化」を目的とする学習法であり、エージェントが「次に何をすべきか」を判断する動的で実践的な性質を持つことがわかります。
また、教師あり学習や教師なし学習が静的なデータセットを扱うのに対し、強化学習は時間軸を含む動的な環境を前提とします。この点が、現実世界での意思決定や自律システム開発において、強化学習が特に重視される理由です。
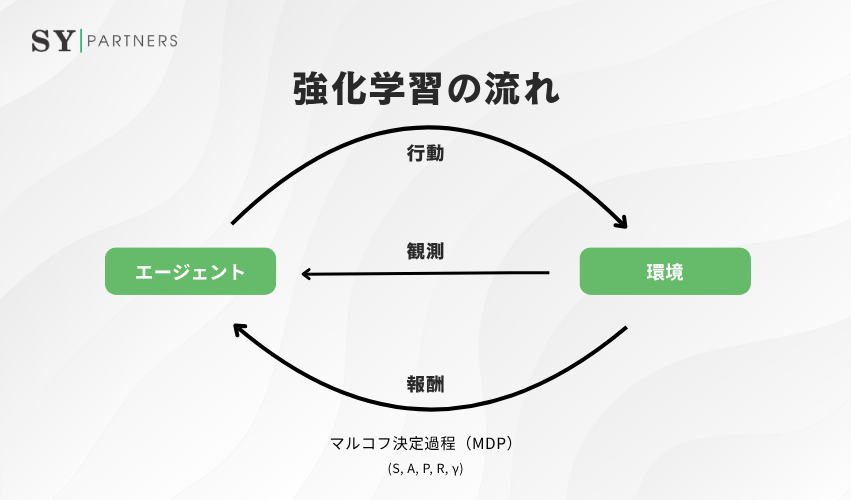
3. 強化学習の流れ
強化学習の中心にあるのは、エージェントが環境との相互作用を通じて報酬を最大化するサイクルです。単純な仕組みながら、この反復によって複雑な意思決定や予測が可能になります。失敗を糧に学び、経験を通して環境を理解し、最適な行動を見つけていく姿は、人間の学習過程にも通じます。
以下では、強化学習における学習サイクルの各段階を整理し、その理論的基盤であるマルコフ決定過程(MDP)の仕組みと役割を解説します。
3.1 観測(Observation)
最初のステップは「観測」です。ここでエージェントは、環境の状態を把握します。状態(State)は、現在の環境を表す情報の集合であり、エージェントが意思決定を行うための出発点になります。
例えば、ロボットであればカメラやセンサーで取得する位置・速度・周囲の状況が状態情報にあたります。自動運転では、交通信号や他車との距離、道路の形状などが状態として観測されます。これらの情報が不正確であったり欠損していると、次の行動選択に誤りが生じるため、観測の質は強化学習の性能を左右する重要な要素です。
3.2 行動選択(Action Selection)
観測した状態に基づいて、エージェントはどの行動を取るかを決定します。このとき、行動方針(Policy)と呼ばれる確率的なルールや戦略が利用されます。方策は、現在の状態における行動選択の確率分布を表し、学習の進行に応じて改善されていきます。
行動選択では、「探索(Exploration)」と「利用(Exploitation)」のバランスが鍵になります。すでに高い報酬をもたらす行動を繰り返すだけでは、より良い行動を見逃す可能性があります。逆に、新しい行動ばかり試しすぎると、安定した報酬を得にくくなります。このバランスを取ることが、強化学習の学習効率と最終的な性能に直結します。
3.3 行動実行(Action Execution)
選択した行動を実際に環境内で実行する段階です。行動は環境に影響を与え、次の状態を変化させます。例えば、将棋AIでは「駒を動かす」という行為、ロボットでは「アームを伸ばす」「前進する」といった物理的動作が該当します。
この行動の実行は、単なる操作ではなく「仮説の検証」とも言えます。エージェントは、過去の経験や方策に基づいて選んだ行動が、果たして有効だったのかを次の段階で評価します。強化学習の本質は、この仮説検証のサイクルを繰り返し、環境の反応を理解していくことにあります。
3.4 報酬受取(Reward Reception)
行動の結果として、環境から報酬が返されます。報酬(Reward)は、その行動がどれほど望ましい結果をもたらしたかを数値的に評価したものです。報酬が大きければその行動は有益であったとみなされ、逆に報酬が小さい、あるいは負の場合は望ましくない行動であったと解釈されます。
報酬設計(Reward Design)は、強化学習における非常に重要な要素です。報酬の定義が適切でなければ、エージェントは意図しない行動を強化してしまうことがあります。たとえば、ゲームAIで「得点を最優先」と設定すると、勝利よりも短期的な得点稼ぎを優先してしまうこともあります。そのため、報酬関数の設計は実際の目的と整合するよう慎重に行う必要があります。
3.5 学習更新(Learning Update)
最後のステップは「学習更新」です。エージェントは、得られた報酬と新しい状態をもとに、自身の方策や価値関数を更新します。ここで利用される代表的な考え方が、価値関数(Value Function) と 行動価値関数(Q-Function) です。これらは「特定の状態(または状態・行動の組み合わせ)が将来的にどれだけの報酬をもたらすか」を表す指標です。
学習更新は、経験を通じて段階的に改善されていくプロセスです。初期の段階ではランダムに近い行動が多く見られますが、試行を重ねるにつれ、エージェントは有効な行動パターンを見出し、より効率的な方策へと収束していきます。この繰り返しが、最適戦略の発見に直結します。
3.6 マルコフ決定過程(Markov Decision Process: MDP)
強化学習の理論的基盤を支えるのが、マルコフ決定過程(MDP) です。これは、エージェントと環境の相互作用を数学的に定義するモデルであり、状態・行動・報酬・遷移確率などの関係を体系的に記述します。
MDPの本質的な特徴は「マルコフ性」と呼ばれる性質にあります。これは、「現在の状態と行動によって、次の状態が確率的に決定する」という性質であり、過去の履歴に依存せず現在の情報だけで将来を予測できることを意味します。この単純さが、強化学習アルゴリズムを数理的に扱いやすくし、計算効率を高めています。
以下にMDPの主要構成要素をまとめます。
名称 | 説明 |
| 状態空間 | 環境のあらゆる状態を表す集合 |
| 行動空間 | エージェントが取ることのできる行動の集合 |
| s,a) ) | 遷移確率 |
| 報酬関数 | 状態と行動の組み合わせに対して得られる報酬の期待値 |
| 割引率 | 将来の報酬をどの程度重視するかを示す係数(0〜1) |
エージェントの目標は、与えられたモデルの中で最適な方策(π*)を探索し、累積報酬(Return)を最大化することにあります。そのために、Q-learning や Policy Gradient をはじめとするさまざまな強化学習アルゴリズムが提案・発展してきました。
4. 強化学習の種類
手法 | モデルの要否 | 更新タイミング | 主な利点 | 主な課題 |
動的計画法 | 必要 | 各ステップごと | 理論的に最適 | モデル構築が必要 |
モンテカルロ法 | 不要 | エピソード終了後 | シンプル・経験的 | 収束が遅い |
TD学習 | 不要 | 各行動後 | 高速・実用的 | 誤差に敏感 |
方策勾配法 | 不要 | 勾配更新 | 連続空間に強い | 勾配分散が大きい |
Actor-Critic法 | 不要 | 同時更新 | 安定・効率的 | 実装が複雑 |
強化学習は多くの研究者によって発展してきた分野であり、目的や環境の特性に応じて多様な手法が提案されています。代表的な基本手法には、動的計画法(Dynamic Programming)、モンテカルロ法(Monte Carlo Methods)、時間差分学習(Temporal Difference Learning)の3つがあります。以下でそれぞれの特徴を簡潔に整理します。
4.1 動的計画法(Dynamic Programming)
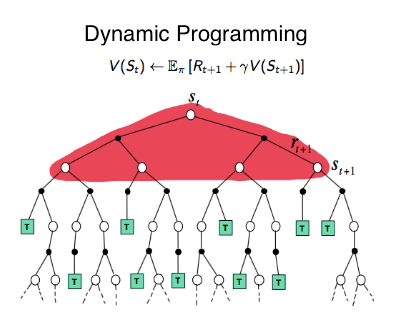
動的計画法では、大きな課題を小さな部分に分割し、離散的な時間ステップでの連続的な意思決定としてモデル化します。各決定は次の状態に基づいて行われ、報酬 r は行動 a、現在の状態 s、および次の状態 s’ の関数として定義されます。
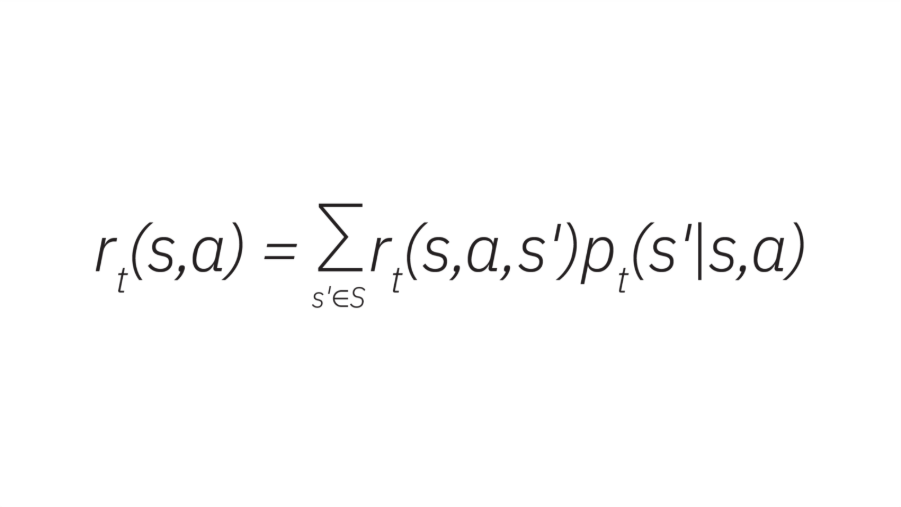
この報酬関数は、エージェントの行動を導く方策の一部として利用されます。最適な方策を求めることが、動的計画法による強化学習の核心であり、ここでベルマン方程式が用いられます。
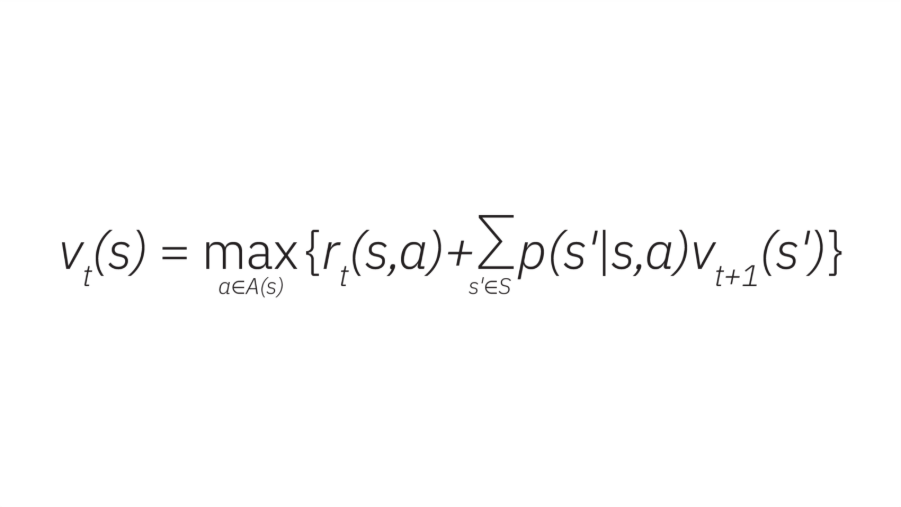
この式は、vt(s) を「時刻 t から終了までの期待累積報酬」と定義します。エージェントは状態 s で即時報酬 rt(s,a) と将来の報酬を評価し、各状態で最適行動を選ぶことで価値関数を最大化します。
4.2 モンテカルロ法(Monte Carlo Methods)
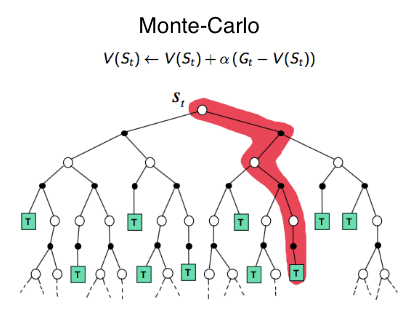
モンテカルロ法は、環境モデルを必要とせず、エピソード(試行)を通じて得られた経験データから学習します。行動と報酬のシーケンスを繰り返しサンプリングし、各状態・行動ペアの平均リターンを求めて価値関数を更新します。
環境のブラックボックス化が可能で、単純な構造でも学習できますが、エピソードが完了するまで更新できないため、学習速度が遅くなる傾向があります。
4.3 時間差分学習(Temporal Difference Learning)
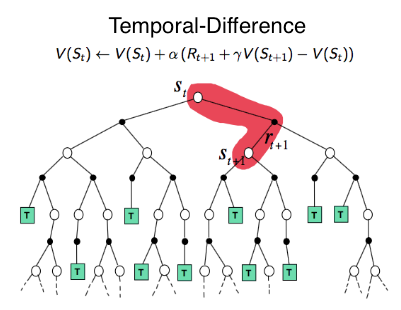
時間差分(TD)学習は、動的計画法とモンテカルロ法の考えを組み合わせた手法です。将来の状態を推定しつつ、各ステップごとに価値関数を更新します。予測値と実際の報酬の差(TD誤差)を利用して学習を進めます。
代表的な手法はSARSA(オンポリシー)とQ-learning(オフポリシー)で、前者は現在の方策に基づき、後者は最適方策を目指して更新します。TD学習は実用的で、現代の多くの強化学習アルゴリズムの基盤となっています。
4.4 方策勾配法とActor-Critic法
方策勾配法(Policy Gradient)は、価値関数を使わずに行動方針そのものを直接最適化します。確率的な方策を学習するため、連続的な行動や高次元環境に適しています。
さらに発展したActor-Critic法では、Actorが行動を決定し、Criticがその行動を評価します。この構造により、学習の安定性と効率性を両立できるのが特徴です。
強化学習の種類は、価値を重視する手法から方策を最適化する手法まで多岐にわたります。
基本的な3系統(動的計画法・モンテカルロ法・TD学習)は、すべての強化学習アルゴリズムの土台であり、これらを理解することが応用や発展的手法への第一歩となります。
5. 強化学習の主要手法
強化学習には数多くのアルゴリズムが存在しますが、その中でも特に基本的で広く応用されているのが Q-Learning(Q学習)、SARSA、そして モンテカルロ法 の3つです。これらはいずれも、エージェントが環境との相互作用を通じて報酬を最大化することを目的としています。それぞれの特徴と違いを理解することは、強化学習の基礎を固める上で重要です。
手法 | 学習タイプ | 更新タイミング | 特徴 | 主な利点 | 主な課題 |
Q-Learning | オフポリシー | 各行動後に更新 | 理論的に最適方策を目指す | モデル不要・収束が早い | 探索バランスが難しい |
SARSA | オンポリシー | 各行動後に更新 | 実際の行動に基づいて学習 | 安定性が高い | 学習速度が遅い |
モンテカルロ法 | モデルフリー | エピソード終了後に更新 | 経験全体から学習 | 構造が単純・直感的 | リアルタイム性が低い |
5.1 Q-Learning
Q-Learningは、最も代表的な強化学習アルゴリズムの一つであり、多くの応用分野で採用されています。エージェントは「状態」と「行動」の組み合わせに基づき、その行動を選択した際に得られる報酬の期待値を表す行動価値関数(Q値)を学習します。
学習の流れとしては、エージェントが行動を選び、環境から報酬を受け取り、その情報を用いてQ値を更新していきます。行動選択は、報酬が最も大きくなるようなQ値を基準に行われます。たとえば、シミュレーション環境で左右の動作を比較し、より高い報酬を与える方向を選ぶことで、バランスを保つ動作を学習します。
Q-Learningの大きな利点は、環境のモデルを必要とせずに最適方策を学べる点にあります。一方で、探索と利用のバランスをとる必要があり、学習初期では不安定な挙動を示すこともあります。
5.2 SARSA
SARSAは、Q-Learningと同様に行動価値関数を学習しますが、更新の仕方に違いがあります。Q-Learningが理論上の最適な次の行動を想定してQ値を更新するのに対し、SARSAは実際にエージェントが取った行動をもとに学習します。
つまり、SARSAは実際の行動と報酬の経験に基づき、より現実的な学習を行います。そのため、オンポリシー学習(on-policy learning)と呼ばれ、現在の方策に忠実に従いながら価値を更新します。
この性質により、SARSAは安全性や安定性が重視されるタスク(例:自律走行の経路学習)でよく用いられます。ただし、学習速度はQ-Learningよりやや遅くなる傾向があります。
5.3 モンテカルロ法
モンテカルロ法は、Q値の更新において次の時点のQ値を参照しないという点が大きな特徴です。エージェントは一連の行動を完了し、報酬を受け取った後に、そのエピソード全体の経験をもとに学習を行います。
すなわち、学習は「一度の試行全体」を単位として進行し、各状態や行動がどれほどの報酬につながったかを後から振り返って更新します。これにより、モデルを持たない環境でも効果的に学習が可能ですが、エピソードの完了を待たなければならないため、リアルタイム性は低くなります。
モンテカルロ法は、報酬構造を直接観測しながら方策を改善していく直感的なアプローチとして、教育的・理論的な理解にも適しています。
Q-Learning、SARSA、モンテカルロ法は、強化学習を理解する上で欠かせない基本アルゴリズムです。Q-Learningは効率的で広く利用され、SARSAは現実的な安定性を重視し、モンテカルロ法は経験に基づいた学習に適しています。これら3つの違いを理解することで、より複雑な手法(DQNやActor-Criticなど)への応用が容易になります。
6. 強化学習の応用例
強化学習は、理論的な枠組みにとどまらず、実社会のさまざまな分野で実用化されています。特に、試行錯誤を通じて最適な行動を学習できるという特性は、動的かつ不確実な環境において大きな強みとなります。以下では、代表的な応用分野を4つ紹介します。
6.1 ロボット制御
ロボット制御は、強化学習の典型的な応用分野です。エージェント(ロボット)が環境と相互作用しながら、自ら動作を最適化していきます。たとえば、歩行ロボットが転倒を繰り返しながら安定した動作を学習したり、マニピュレータが物体を正確に掴む動作を自動的に習得します。
シミュレーション環境を利用して安全かつ効率的に学習できる点も、ロボット分野における強化学習の大きな利点です。
6.2 自動運転
自動運転技術では、強化学習が車両の意思決定や経路最適化に活用されています。たとえば、信号、歩行者、障害物など複雑な交通状況において、エージェントが最適な加減速・方向転換を学びます。
報酬関数を安全運転や燃費効率に設定することで、システムは人間の運転よりも安定した判断を下すことが可能になります。現在では、シミュレーションベースの学習と実車データを組み合わせたハイブリッド型の学習も進められています。
6.3 ゲームAI
ゲーム分野は、強化学習が大きく発展した領域です。代表例としては、囲碁AI「AlphaGo」やチェス、将棋AIなどが挙げられます。エージェントが自己対戦を繰り返すことで最適な戦略を学び、人間を上回るレベルの意思決定が可能になりました。
また、近年ではeスポーツやシミュレーションゲームでも、プレイヤーの行動に適応するAI開発が進んでおり、より自然な対戦体験を実現しています。
6.4 金融・投資分野
金融分野では、強化学習を用いて自動売買やポートフォリオ最適化が行われています。市場の変動に応じて最適な売買判断をリアルタイムで更新し、長期的な利益を最大化します。
特に、リスク管理やポジション制御に強化学習を組み込むことで、従来の統計モデルでは難しかった柔軟な意思決定が可能になります。
強化学習は、物理的動作から抽象的な意思決定まで、幅広い分野で応用が進んでいます。ロボットや自動運転などの実世界システムだけでなく、ゲームや金融のようなデジタル領域にも柔軟に対応できる点が強みです。今後は、シミュレーション技術や大規模データとの統合により、さらに実用性が拡大すると考えられます。
おわりに
強化学習は、AIが自律的に行動を学び、環境との相互作用を通じて最適な戦略を見つけ出すための強力な枠組みです。エージェントは「報酬」を手がかりに試行錯誤を繰り返し、成功と失敗の経験から行動方針を改善していきます。この学習過程は、生物の学習メカニズムにも通じるものであり、人間が経験を通して成長していくプロセスに近いといえます。
その理論は非常にシンプルですが、応用範囲は驚くほど広く、ロボット制御や自動運転、ゲームAI、金融取引の最適化など、多様な分野で実用化が進んでいます。特に、未知の環境下でも柔軟に対応できる点が強化学習の大きな強みであり、現実世界の複雑な問題解決においても高いポテンシャルを発揮しています。
よくある質問
報酬設計は、エージェントの行動を直接導く「指針」となる部分であり、わずかな設計の誤りが行動の歪みにつながります。報酬の定義を誤ると、エージェントは人間が意図していない「報酬を最大化する行動」を取ることがあります。これは「報酬ハッキング(Reward Hacking)」と呼ばれる現象です。
例えば、自動運転のタスクで「目的地に速く到達すること」を唯一の報酬とすると、信号無視や危険運転が強化されてしまう可能性があります。報酬の定義が目的と乖離していると、学習結果も意図から外れてしまうわけです。
したがって、報酬設計では「目的との整合性」と「学習の安定性」を両立させる必要があります。報酬が細かすぎると過学習を引き起こし、単純すぎると探索が進まないため、抽象度と具体性のバランスを慎重に取ることが求められます。
強化学習では、環境との相互作用を通じて知識を得るため、試行回数が膨大になりがちです。このため、学習効率を高めるさまざまな技術が開発されています。
代表的なのが、経験再利用(Experience Replay)とターゲットネットワーク(Target Network)です。
前者は、過去の経験データを再利用して学習の安定性を高める手法であり、後者は、更新対象のネットワークと参照ネットワークを分離することで学習の発散を防ぎます。
さらに、転移学習(Transfer Learning)の導入により、すでに学習済みの環境やタスクで得られた知識を新しい課題へ再利用することも可能になっています。これにより、ゼロからの学習を行うよりも大幅にサンプル効率を改善できます。
加えて、近年では模倣学習やメタラーニングとの統合も進み、データ量が限られる環境下でも効果的な学習が可能になっています。
深層強化学習(DRL)は、強化学習の探索能力と深層学習の表現力を組み合わせたアプローチです。これにより、従来の手法では扱えなかった高次元データ(画像・音声・センサー入力など)を直接処理できるようになりました。
従来の強化学習は、状態空間が大きくなると計算量が爆発し、現実的な環境を扱うのが困難でした。しかし、ディープニューラルネットワークが価値関数や方策を近似することで、状態空間の圧縮と汎化が可能となりました。
代表例として、DeepMindが開発した DQN(Deep Q-Network) は、ゲーム画面のピクセル情報だけを入力として、スーパーヒューマンレベルのプレイを実現しました。また、「AlphaGo」では強化学習にディープネットワークを組み合わせることで、人間の直感的判断に近い戦略学習が可能となりました。
マルコフ決定過程(MDP)は、「現在の状態と行動によって次の状態が確率的に決まる」という「マルコフ性」を前提としています。
このモデルは理論的に美しい枠組みですが、現実世界では常に成立するわけではありません。環境のノイズ、未観測変数、外乱などの影響により、状態遷移が単純な確率関数で表せない場合が多いからです。
この課題に対応するために、部分観測マルコフ決定過程(POMDP: Partially Observable MDP)が利用されます。これは、完全な状態が観測できない前提のもとで、確率的に状態を推定する枠組みです。また、ベイズ推定や確率的フィルタリング(例:カルマンフィルタ、粒子フィルタ)を組み合わせることで、不確実な環境下でも信頼性の高い方策を構築できます。
つまり、MDPは「理論の骨格」であり、実務では拡張モデル(POMDP、確率的モデル化)を併用して現実の複雑さに対応するのが一般的です。
最大の課題は、安全性とサンプル効率の両立です。
強化学習は試行錯誤を通じて学ぶため、実環境での誤動作が重大なリスクにつながることがあります。特に、自動運転や医療ロボットのような分野では「失敗」が許されないため、直接実環境で学習させることが困難です。
このため、まずシミュレーション環境で学習を行い、その後実機に適用する「Sim-to-Real(シムトゥリアル)」アプローチが採用されます。しかし、シミュレーションと現実のギャップを埋めること(ドメイン適応)は依然として難しい課題です。
さらに、報酬がまれなタスク(Sparse Reward)では、エージェントが報酬信号を得るまでに多大な試行を要し、学習が停滞することがあります。これを解決するために、模倣学習(Imitation Learning) や カリキュラム学習(Curriculum Learning) などが用いられ、効率的な探索を促進しています。
安全性・効率性・汎化性能の三立を実現することこそ、今後の強化学習研究の中心的テーマといえるでしょう。
