 EN
EN JP
JP KR
KR
TD学習(Temporal Difference Learning)とは?TD誤差・TD(0)・SARSAとQ-learningまでわかりやすく解説
強化学習を学び始めると、多くの人が最初につまずくのが「価値(Value)や行動価値(Q)をどのルールで更新するのか」という点です。方策や報酬設計より前に、この更新の仕組みを理解していないと、アルゴリズム同士の違いが数式の暗記に見えてしまいます。そこで頻出するのが TD学習(Temporal Difference Learning) であり、Q-learning や SARSA をはじめとする多くの実用的な強化学習アルゴリズムの共通基盤になっています。TD学習の最大の特徴は、エピソードの終わりを待たず、1ステップごとに学習を進められる点にあります。
この「毎ステップ学べる」仕組みの中心にあるのが、TD誤差(TD error)=報酬予測誤差です。直感的には、「自分が予想していた未来」と「実際に観測された未来(報酬+次状態の推定値)」のズレを、その場で少しずつ修正していく学び方だと捉えられます。モンテカルロ法(MC)のように結果がすべて出そろうまで待つ必要はなく、かつ動的計画法(DP)のように環境モデルを前提ともしません。このためTD学習は、経験から直接学びつつ、推定値を使って効率よく更新できる手法として、「MCとDPのいいとこ取り」と表現されることが多いのです。
本記事では、TD学習の基本的な考え方から、TD誤差と TD(0) の更新式、SARSA と Q-learning の違い、直感で理解できるミニ例、そして最小限の Python コード例までを扱います。数式は理解を助ける一方で、「意味のズレ」を生みやすい部分でもあるため、要点は言葉・表・具体例を軸に整理し、学習目的でも実務目的でも迷わず読み進められる構成にします。
1. TD学習とは?
TD学習(Temporal Difference Learning)は、強化学習における代表的な学習手法の一つで、将来得られる報酬の予測値と、実際に観測された報酬および次状態の価値との差(TD誤差)を用いて価値関数を更新します。エージェントは行動と状態遷移を繰り返しながら、その都度予測を修正していくため、環境との相互作用を通じて段階的に意思決定の精度を高めていきます。この更新は逐次的に行われ、学習のたびにモデル全体を待つ必要がありません。
TD学習の大きな特徴は、エピソードが完全に終了するのを待たず、各ステップごとに学習できる点にあります。そのため、モンテカルロ法のように最終結果が確定しないと更新できない手法と比べて、オンライン学習に適しており、動的で変化の激しい環境でも効率よく学習を進められます。この性質により、TD学習は実用性が高く、Q-learning や SARSA などの代表的な強化学習アルゴリズムの基盤として広く利用されています。
特徴
| 観点 | 内容 |
|---|---|
| 学習タイミング | 各ステップごとに即時更新が可能 |
| 必要な情報 | 現在の報酬と次状態の価値予測 |
| モンテカルロ法との違い | エピソード終了を待たずに学習できる |
| 適した環境 | 動的・連続的・長いエピソードを持つ環境 |
| 代表的アルゴリズム | Q-learning、SARSA など |
2. TD学習(Temporal Difference Learning)と報酬予測誤差の関係
TD学習は、環境の遷移確率や報酬の仕組みを事前に知らなくても学習できるモデルフリー型の強化学習手法であり、「毎ステップ学習できる」という点が大きな特徴です。通常の学習手法では、ある程度結果が出そろってから評価を行いますが、TD学習では1歩行動するごとに、その時点で得られた情報を使って価値を更新してよいという考え方を取ります。これにより、学習は連続的かつオンラインに進み、長いエピソードや終わりの見えないタスクでも安定して改善を重ねることができます。
この逐次学習を可能にしている中核的な概念が、報酬予測誤差(TD誤差)です。TD誤差は、「今まで予測していた価値」と「実際に得られた報酬+次状態の予測価値」とのズレを表します。エージェントはこのズレをフィードバックとして使い、自分の価値予測がどれだけ間違っていたかを把握し、次の行動や判断に反映させます。つまりTD学習とは、予測と現実の差分を少しずつ埋めていく学習プロセスだと捉えることができます。
TD学習をより直感的に理解するためには、よく比較される2つの手法、モンテカルロ法(MC)と動的計画法(DP)と並べて考えるのが効果的です。3つの手法は「いつ更新するか」「何を使って更新するか」という点で性格がはっきり分かれており、その違いを見ることで、TD学習の立ち位置が明確になります。
| 手法 | いつ更新する? | 環境モデルは必要? | 更新の考え方 | 得意 / 苦手 |
|---|---|---|---|---|
| モンテカルロ法(MC) | エピソード終了後 | 不要 | 実際の総リターンを平均して学習 | 終わりのないタスクが苦手/分散が大きい |
| 動的計画法(DP) | 任意(計画的に) | 必要 | モデルを用いた Bellman 更新 | モデルがない現場では使いにくい |
| TD学習 | 毎ステップ | 不要 | 次状態の推定値を使って更新(ブートストラップ) | 継続タスクに強い/学習が速い |
ここでTD学習が、しばしば「MCとDPのいいとこ取り」と表現される理由は非常にシンプルです。
まず、MCと同様に環境モデルを必要とせず、実際の経験データから直接学習できます。一方で、DPのように次状態の価値という推定値を使って更新(ブートストラップ)するため、結果がすべて揃うのを待つ必要がありません。その結果、TD学習は毎ステップ更新が可能となり、学習速度と実用性の両立を実現しています。
なぜTD学習は「モデルフリー」なのか
TD学習がモデルフリーと呼ばれる理由は、環境の遷移確率 P(s′∣s,a)や報酬の分布といった環境モデルを事前に仮定・推定する必要がない点にあります。エージェントは、実際に環境の中で行動し、「状態 → 行動 → 報酬 → 次状態」という一連の経験から、その場で価値を更新していきます。これは、環境のルールを数式として与えられる前提ではなく、観測された結果だけを信頼して学ぶアプローチです。
言い換えると、TD学習は「ルールを教えてもらって計算する」のではなく、「やってみた結果をもとに予測を修正する」学習方法だと言えます。モデルを持たないため、環境が複雑・不確実・変化しやすい場合でも適用しやすく、現実世界の問題にそのまま持ち込みやすいという利点があります。この性質が、TD学習を多くの実用的な強化学習手法の基盤にしている理由の一つです。
なぜTD学習は「継続タスク(non-episodic)」に向くのか
TD学習が継続タスクに向いている最大の理由は、エピソードの終了を待たず、1ステップごとに学習を進められる点にあります。モンテカルロ法のように「一連の行動が終わってからまとめて評価する」必要がないため、タスクに明確な終点が存在しなくても、学習を止めずに回し続けることができます。
現実の問題の多くは、ゲームの1プレイのように明確な終わりがあるわけではありません。リアルタイム制御、常時稼働するサービスの最適化、継続的に状態が変化する環境などでは、「終わりを待つ」こと自体が非現実的です。TD学習は、そうした「終わらない問題」を前提に設計された学習手法であり、学習速度と安定性のバランスが取りやすい点が、実用上の大きな強みとなっています。
3. TD誤差とTD(0)更新式
TD学習の中心は「Bellmanの考え方」と「TD誤差(=報酬予測誤差の計算形)」です。
まず、状態価値関数の土台(Bellman方程式)は次の形です。
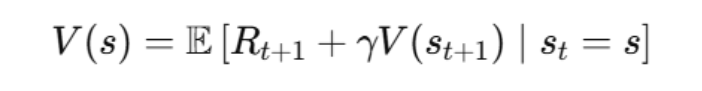
行動価値関数(方策 (\pi) のもと)も同様に、次を使う形で書けます。
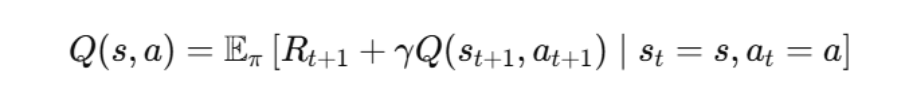
そしてTD(0)で使うTD誤差は、次の「観測ターゲット − 既存予測」です。
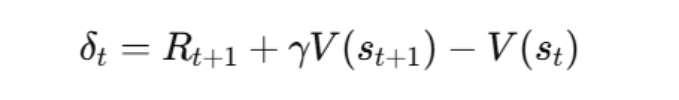
更新は誤差に学習率を掛けて反映します。
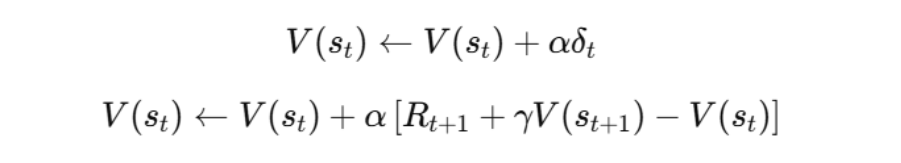
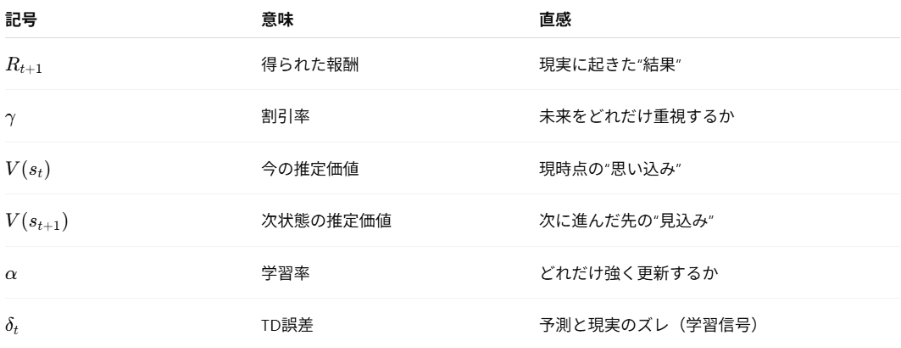
記号が混乱しやすいので、意味を表で揃えると理解が速いです。
4. SARSAとQ-learning:同じTDでも「どの方策を学ぶか」が違う
TD系の代表が SARSA(オンポリシー) と Q-learning(オフポリシー) です。どちらも「報酬+次の推定値−現在の推定値」という形の誤差で QQQ を更新しますが、決定的に違うのは次の状態で参照する行動です。
ここが違うだけで、学ぶ方策の性質(安全寄りか、最適寄りか)が変わります。さらに言うと「探索の仕方」を学習ターゲットに含めるかどうかが分岐点です。探索は現実の学習では不可欠ですが、探索は同時にリスクや遠回りも持ち込みます。その扱いが、SARSAとQ-learningの違いとして現れます。
4.1 SARSA(On-policy TD Control)
SARSAは、いま実際に使っている行動方策(たとえば ε-greedy)に従って選ばれた次の行動At+1をそのまま使います。
オンポリシーというのは、「探索(εでランダムに行動する)も含めた実際の方策」を評価して学ぶ、という意味です。探索のせいで危険な行動を取る可能性があるなら、そのリスクも含んだ値を学びます。結果として、ノイズや危険がある環境では、探索込みの現実に即した(ときに安全寄りの)方策に落ち着きやすい、という説明がよくされます。
例えば、探索でたまに危険な方向へ逸れる可能性がある状況では、「最適に見える行動」よりも「探索込みでも事故りにくい行動」を好むような価値が学習されやすいです。つまりSARSAは、実運用に近い状況(探索が混ざる現実)をそのまま評価に取り込む点が特徴です。
4.2 Q-learning(Off-policy TD Control)
Q-learningは、次状態で取り得る行動のうち「最大価値」を参照して更新します。つまり、実際に次に何をしたかではなく、「最適に振る舞うなら何をするか」をターゲットにします。
オフポリシーというのは、「実際に動く方策(探索)と、学ぶ対象(最適方策)」を分離できるということです。探索しながらデータを集めつつ、学習ターゲットは常に貪欲(最大)を向くので、理論条件が揃えば最適な方策へ近づきやすいという性質があります。直感的には「現実の行動は探索でブレてもいいが、学習の目標は常に最適を目指す」という姿勢です。
一方で、探索が強い・環境が不安定・関数近似を使う、といった状況では、推定が暴れたり、学習が不安定になったりすることもあり得ます。ここは“最適を目指す強さ”の裏返しで、環境条件や実装条件によって扱い方が難しくなるポイントでもあります。
5. 直感でわかるミニ例(TD更新の流れ)
TD更新は、仕組み自体はとても素朴です。たとえばグリッド世界で、通常マスは −1-1−1、ゴールは +10+10+10、毒は −10-10−10 とします。初期は V(s)=0V(s)=0V(s)=0 だとします。
あるステップで S1→S2に移動して報酬 −1-1−1 を得たとき、単純化して γ=0とすると(未来を無視する設定):
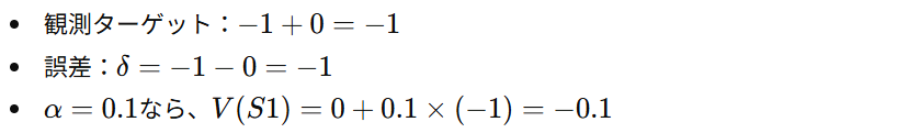
こうして「S1はあまり良くないところだ」と学び始めます。ここで大事なのは、たった1回の経験では「たまたま悪かった」可能性があるため、更新が「少しだけ」になっている点です。
次に別の遷移を経験すると、その経験に合わせて別の状態価値も少しずつ更新されます。これを大量に繰り返すと、価値は「その方策で動いたときの期待リターン」に近づいていきます。
さらに γ を 0 ではなく 0.9 のように大きくすると、次状態の価値が効くため、「今は-1でも、次にゴールへ行けるなら悪くない」といった長期目線の更新になります。つまり同じ経験でも、γ の設定によって「未来をどれだけ織り込むか」が変わり、価値更新の方向性や速度が変わります。TD学習は、こうした設計パラメータを通じて“どんな学びをしたいか”を調整できるのも特徴です。
6. TD更新の超シンプルコード例(Python)
TD学習(Temporal Difference Learning)の理解でつまずきやすいのは、「更新式が実際にどう動くのか」をイメージしにくい点です。数式だけを見ると抽象的ですが、コードに落とすと「今の推定値を、次状態の推定と報酬で少しずつ修正していく」だけだと分かります。以下は、TD(0)の更新式をそのまま実装した最小限のPython例です。
このコードはTD(0)の更新式
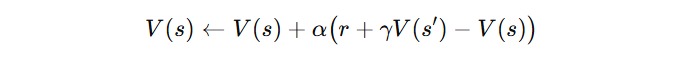
をそのまま順に適用しています。
経験列の中で報酬が発生しているのは (D → E) だけなので、まずは状態Dの価値が直接的に更新されます。その後、同様の遷移を何度も経験することで、Dの価値上昇がC、Bへと徐々に伝播していきます。
# TD(0) update examplestates = ['A', 'B', 'C', 'D', 'E']V = {s: 0.0 for s in states}alpha = 0.1gamma = 0.9# (state, reward, next_state)experience = [('B', 0, 'C'),('C', 0, 'D'),('D', 1, 'E'), # terminal-ish example]for s, r, s_next in experience:V[s] = V[s] + alpha (r + gamma V[s_next] - V[s])print(V)
TD学習の本質は、「将来の推定値を使って、現在の推定をオンラインで修正する」点にあります。モンテカルロ法のようにエピソード終了を待つ必要がなく、1ステップごとに学習できるため、実用アルゴリズムの基盤として広く使われています。より現実的な設定では、多様な遷移を多数回サンプリングすることで、各状態価値は「その方策に従ったときの期待リターン」へと収束していきます。
おわりに
TD学習は、強化学習における更新ルールを理解するうえで、最も重要な土台の一つです。エピソードの終わりを待たずに学習できるのは、TD誤差(報酬予測誤差)という「予測と観測のズレ」を、各ステップで即座に捉え、少しずつ修正していく仕組みを持っているからです。この逐次更新によって、学習はオンラインに進み、終わりの見えない継続タスクでも安定して回し続けることができます。その結果、TD学習は理論だけでなく実運用にも強く、多くの実用的な強化学習アルゴリズムの基盤として採用されています。
また、同じTD系アルゴリズムであっても、SARSA と Q-learning では「次状態でどの行動価値を参照するか」が異なります。この違いは、学習される方策がオンポリシーかオフポリシーかという性質の差につながります。SARSA は実際に選択した行動を含めて学習するため探索の影響を受けやすく、挙動は比較的安定します。一方、Q-learning は常に最大価値を学習ターゲットにするため、理想的な方策に近づきやすい反面、環境によっては不安定になることもあります。この違いを言葉で説明できるようになると、アルゴリズム選択の判断が一段ラクになります。
TD学習は、数式を暗記するよりも、「何を予測し、何と比べ、どれだけ直すか」という3点で捉えると理解が崩れません。TD誤差とは「観測された未来」と「現在の予測」との差であり、更新とはその差分だけ予測を少し寄せる操作にすぎません。この視点で見ると、TD(0)、SARSA、Q-learning はすべて同じ枠組みの中に整理でき、手法ごとの違いも自然に理解できるようになります。