 EN
EN JP
JP KR
KR
人工ニューラルネットワークとは?層構造・学習原理・限界まで体系整理
人工ニューラルネットワークを実務で扱う際に重要なのは、精度の数値そのものよりも、「なぜ当たっていて、なぜ外れるのか」を運用できる形で説明できる状態を作ることです。ANNは高い表現力を持つ一方、学習はデータ分布と最適化条件に強く依存し、前処理のスケール差、出力の意味づけ、損失設計、正規化・正則化、初期化や学習率といった要素のわずかなズレが、収束性・汎化・推論レイテンシにそのまま跳ね返ります。PoC段階では「動いた」「当たった」で前に進めますが、本番に入ると、学習の再現性、指標の安定性、監視とアラート設計、障害時の切り分けが要求され、ブラックボックスとしての採用は破綻しやすくなります。したがって、層を単なる部品表として見るのではなく、表現をどこで作り、どこで制約を与え、どこで意味を確定させたかを説明できる専門言語として捉えることが、実務上の必須条件になります。
本記事では、ANNを「層の合成写像」として整理し、学習が成立する流れ(順伝播→損失→逆伝播→更新)を工程として捉え直します。あわせて、「表現できる」ことと「学習できる」ことが別である点を前提に、表現力・最適化容易性・計算制約の三者がどのようにトレードオフを形成するかを俯瞰します。この整理を先に置くことで、性能が伸びないときに闇雲に層を足す、ハイパーパラメータを総当たりする、といった探索型の泥沼に入りにくくなります。代わりに、入力仕様の歪み、出力定義と損失の不整合、勾配の不安定化、過学習の誘発箇所といった原因仮説を立てやすくなり、検証が診断として回ります。結果として、改善は個人の勘に依存しにくくなり、レビューや再現実験、運用監視まで一貫した設計判断として積み上がるようになります。
1. 人工ニューラルネットワークとは
人工ニューラルネットワーク(ANN: Artificial Neural Network)は、生物の神経回路を数学的に抽象化した計算モデルであり、入力から出力までの変換を、複数の層に分割した合成写像として表現します。直観的には「入力を段階的に加工して、最終的に分類や回帰の答えを出す装置」ですが、より精密には、重み(係数)を学習によって最適化し、目的関数(損失)を最小化するように関数形そのものを調整する枠組みです。ここでのポイントは、ANNが単なる線形モデルの延長ではなく、非線形変換を挟むことで、入力空間では線形分離できない構造を表現できるように設計されている点にあります。
ANNの本質は「線形変換と非線形活性化を層として積み重ねる」ことにあります。線形変換だけをどれだけ重ねても、全体としては一つの線形変換に畳み込まれてしまい、表現力は増えません。そこで活性化関数を挟み、層をまたぐたびに表現空間を折り曲げることで、複雑な決定境界や回帰関数を学習可能にします。実務でANNが強いのは、特徴量設計を人間が固定せずとも、層が表現を自動的に組み替え、タスクに有利な表現へ寄せられる点にありますが、同時にこの自由度の大きさが、過学習や不安定化の温床にもなります。
1.1 人工ニューラルネットワークの層構造
人工ニューラルネットワークは、層状に接続されたノード(ニューロン)集合として構成されます。入力層がデータを受け取り、隠れ層が表現変換を繰り返し、出力層がタスクに対応する形式で結果を生成します。層構造の分業を明確にしておくと、設計・デバッグ・運用が整理され、何をどの層に期待しているかを説明しやすくなります。特に、入力のスケーリングや表現の容量配分、出力の意味づけ(確率として扱うのか、連続値として扱うのか)を層の責務として切り分けることが、実務での再現性に直結します。
| 層 | 役割 | 典型的な設計観点 |
|---|---|---|
| 入力層(Input Layer) | 生データを受け取り、次層が扱える形に整える | 特徴量定義、正規化・標準化、欠損・カテゴリ処理 |
| 隠れ層(Hidden Layer) | 表現変換を担い、非線形なパターンを学習する | 層数・幅、活性化、正則化、正規化、計算量 |
| 出力層(Output Layer) | 予測の形式を確定し、損失関数と整合させる | Softmax/Sigmoid/Linear、出力次元、較正・閾値 |
この層構造の中核にある繰り返しは「線形変換 + 非線形活性化」です。層を増やすことは、単純に計算回数を増やすのではなく、表現空間を段階的に再配置して、タスクが解きやすい幾何へ変形することに等しいです。したがって、層設計は「どれだけ大きくするか」ではなく「どこで何を表現させ、どこで制約をかけるか」という工学設計として扱うと、改善の根拠が立ちやすくなります。
1.2 ニューロン(パーセプトロン)の数理構造
ニューロン(パーセプトロン)は、入力ベクトルに対して重み付き和を取り、バイアスを加え、活性化関数で非線形変換する最小単位です。直観的には「複数の入力を一つの信号に統合して変換する」操作ですが、数理的には、線形部分が超平面による分離や回帰の基本形を作り、非線形部分が表現力を拡張します。パーセプトロンが多数集まって層を構成し、それが積み重なることで、入力空間では単純でない構造も段階的に捉えられるようになります。
数式で書くと、単一ニューロンは次の形で表されます。ここで重みは入力特徴の寄与を、バイアスは基準値(オフセット)を、活性化関数は非線形性を担います。

層全体として見ると、入力ベクトル x を次の層へ送る変換は行列演算でまとめられます。これにより、実装上はバッチ処理が可能になり、学習は大規模な最適化問題として扱えます。
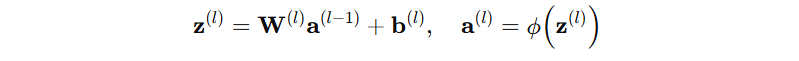
2. 人工ニューラルネットワークの学習原理
ANNの学習は、端的に言えば「出力の誤差を小さくするように重みを調整する」最適化です。ただし、層が重なると誤差がどの重みに由来するかは直接には見えません。そこで、順伝播で予測を作り、損失関数で誤差を数値化し、逆伝播で各パラメータに対する勾配を計算し、勾配降下法で更新する、という連鎖で学習が成立します。この連鎖が安定して回るかどうかは、モデルの表現力だけでなく、活性化関数、初期化、正規化、学習率、バッチサイズなどの設計要素に強く依存します。
学習原理を「誤差最小化プロセス」として押さえると、なぜ微分が必要で、なぜ深層化が難しくなり、なぜ勾配消失が起きるのかが一本の線で繋がります。つまり学習を理解するとは、アルゴリズムを覚えることではなく、最適化の流れがどこで歪みやすいかを予測できることに近いです。
2.1 ニューラルネットワークの誤差最小化プロセス
学習は一連の処理として整理できます。処理の並び自体は定型ですが、各段の設計が不適切だと、誤差が下がらない、勾配が不安定、汎化しないといった形で破綻します。
学習が進む基本の流れは次の通りです。
・順伝播(Forward Propagation):入力から出力まで層を通して予測を計算します。
・誤差計算(Loss Calculation):予測と正解の差を損失関数で数値化します。
・逆伝播(Backpropagation):損失を各パラメータで微分し、勾配を計算します。
・重み更新(Weight Update):勾配降下法などでパラメータを更新します。
この流れを「反復最適化」として捉えると、学習が失敗する原因が切り分けやすくなります。順伝播側で表現が不足しているのか、損失の定義がタスクとずれているのか、逆伝播で勾配が消えているのか、更新則や学習率が強すぎるのか、といった観点で診断できるため、改善が場当たり的なハイパーパラメータ調整から脱しやすくなります。
2.2 勾配降下法と逆伝播の役割
逆伝播は「誤差を各パラメータへ配分する」ための計算機構であり、勾配降下法は「その配分に従って更新する」ための最適化手段です。ここで微分が必要なのは、損失がパラメータの連続関数として定義されている限り、改善方向を局所的に示す情報が勾配だからです。勾配は、どのパラメータをどちらにどれくらい動かすと損失が下がりやすいかを示すため、更新則はこの情報を用いて最適化を進めます。逆伝播は連鎖律を使って効率よく勾配を計算し、深層でも計算量を現実的に抑える役割を担います。
2.2.1 なぜ微分が必要か
損失関数 (L(\theta)) を最小化したいとき、パラメータ (\theta) を少し動かした場合の損失の変化率が (\nabla_\theta L) です。これが局所的な最急降下方向を与えるため、更新は通常「勾配の反対方向」へ進みます。直観的には、損失という地形の傾きに沿って下る操作であり、傾きが分からなければ、探索はランダムウォークに近づいてしまいます。ANNが大規模になればなるほど、ランダム探索は計算量的に成立しないため、微分可能な設計と勾配に基づく更新が前提になります。
2.2.2 層が深くなると何が難しくなるか
深層化は表現力を増やす一方、最適化を難しくします。理由は単純で、層が増えるほど合成写像が複雑になり、損失地形が非凸かつ多峰性になりやすく、局所的な勾配情報だけでは進み方が不安定になりやすいからです。さらに、勾配は層をまたいで連鎖律で伝播するため、途中の活性化や重みのスケールが不適切だと、勾配が極端に小さくなったり大きくなったりします。これが収束遅延や発散の主要因になり、深層ほど初期化・正規化・学習率設計の重要性が増します。
2.2.3 勾配消失問題
勾配消失は、逆伝播で勾配が層を遡る過程で指数的に小さくなり、手前の層がほとんど更新されなくなる現象です。特に飽和しやすい活性化関数(SigmoidやTanhの一部領域)や、重みのスケールが小さすぎる場合に起こりやすく、深層では顕著になります。結果として、上位層だけが変化して手前層が学べず、表現学習が途中で止まったように見える状態になります。これに対して、ReLU系活性化の採用、適切な初期化、正規化(バッチ正規化等)、残差接続などが、学習信号を保つための工学的対策として位置づけられます。
2.3 学習過程の構造整理
学習を要素に分解すると、各概念の役割と数理的意味が見通しやすくなります。単語として理解するのではなく「どの最適化対象に、どの変換が入っているのか」を意識すると、設計の一貫性が上がります。
| 概念 | 役割 | 数理的意味 |
|---|---|---|
| 重み | 関係性の強さ | 係数(行列要素) |
| バイアス | 基準値調整 | 定数項(平行移動) |
| 活性化関数 | 非線形性導入 | 関数変換 (\phi(\cdot)) |
| 損失関数 | 誤差測定 | 最適化対象 (L(\theta)) |
3. 人工ニューラルネットワークの表現能力
ANNの強みは、非線形変換を層として積み重ねることで、複雑な関数クラスを表現できる点にあります。線形モデルが扱えるのは入力空間での線形分離や線形回帰に限られますが、ANNは表現空間を層ごとに再構成し、入力空間では線形でない関係も、ある中間表現では線形に近い形へ変形できます。ここで「深さ」は、単なるパラメータ増ではなく、抽象度の異なる特徴を階層的に構成する手段として働きます。
表現能力を語るときに注意したいのは「表現できる」ことと「学習できる」ことが別である点です。理論的に表現可能でも、最適化が難しければ実用上の意味は薄れます。したがって実務では、表現力だけでなく、学習が安定して収束し、未知データに汎化する形で表現が獲得できるか、という観点で層構造を評価します。
3.1 非線形表現と関数近似能力
線形モデルは、入力の線形結合で予測を作るため、表現できる関数形は限定されます。ANNは活性化関数により非線形性を導入し、層を重ねることで、入力の局所的な変化に対して柔軟に応答できる関数を構成します。多層化の意義は、単に複雑にすることではなく、低次のパターンから高次のパターンへと表現を積み上げ、タスクに必要な抽象表現を自動的に構築できる点にあります。実務の観点では、入力特徴の設計負担を減らしつつ、同時にデータが持つ構造を学習に取り込めることが性能へ繋がります。
万能近似定理は「十分な幅を持つネットワークは任意の連続関数を近似できる」という方向性を示しますが、これは学習の容易さを保証するものではありません。近似可能性は理論的な上限であり、実際にはデータ量、ノイズ、最適化手法、正則化の設計が、到達可能な性能を制約します。したがって、万能近似という言葉を「何でもできる」ではなく「表現力の器は持つが、器を使い切るには学習設計が必要」と捉える方が、実務的には安全です。
3.2 層の深さと抽象度の関係
深層化によって、層ごとに抽象度が変化する表現が得られやすくなります。画像認識を例にすると、初期層は局所的なエッジやテクスチャのような低次特徴を捉え、中間層は部品やパターンの組み合わせを表し、終端近くは物体カテゴリのような高次概念に対応しやすくなります。これは「層が深いほど抽象的になる」という単純な話ではなく、学習が目的関数に沿って最適化された結果として、層ごとの表現が階層的に分化しやすい、という理解が適切です。
| 層 | 画像認識での役割例 | 抽象度 |
|---|---|---|
| 第1層 | エッジ検出 | 低 |
| 中間層 | パーツ認識 | 中 |
| 最終層 | 物体分類 | 高 |
4. 人工ニューラルネットワークの主要な派生構造
ANNは基本形(全結合中心)だけでなく、データの構造に合わせて帰納バイアスを強めた派生構造が発展してきました。画像には空間構造、言語や時系列には順序と依存、現代の生成AIには大規模データと並列計算という前提があり、それぞれに適した構造が採用されます。派生構造を理解することは、単なる流行の把握ではなく「どの前提をモデルに埋め込むと学習が成立しやすいか」を見極めることに直結します。
4.1 畳み込みニューラルネットワーク(CNN)
CNNは、空間的局所性とパラメータ共有を前提に、画像処理で強い性能を発揮する構造です。畳み込みにより局所特徴を抽出し、それを階層的に統合することで、少ないパラメータで効率よく学習しやすくなります。
CNNを特徴づける代表要素は次の通りです。
・局所受容野:局所領域から特徴を抽出し、空間構造を活かします。
・重み共有:同じフィルタを全位置に適用し、パラメータ効率を高めます。
・画像処理特化:平行移動に対する頑健性など、画像に整合した前提を置きます。
これらの要素は、単に「画像に強い」ではなく、画像が持つ統計的構造をモデルに取り込み、学習を成立させるための工学的設計だと捉えると、なぜ有効なのかが腑に落ちます。
4.2 再帰型ニューラルネットワーク(RNN)
RNNは、系列データに対して状態を保持しながら処理することで、時間的・文脈的依存を表現する構造です。入力が順序として意味を持つタスクで、前後関係を表現に取り込めることが特徴です。
RNNの代表的な性質は次の通りです。
・時系列処理:時間方向の依存を扱い、予測に文脈を反映します。
・状態保持:過去情報を内部状態として持ち、系列全体の情報を統合します。
・言語処理:単語列の依存や文脈の影響を表現しやすい枠組みです。
ただし、長期依存の学習は難しく、勾配消失などが問題化しやすいため、実務では系列長の扱い、正則化、設計の工夫が重要になります。
4.3 Transformerと現代生成AI
Transformerは、Attention機構を中心に据え、系列内の依存を「状態の逐次更新」ではなく「相互参照」で扱う構造です。並列処理が可能な点が大規模学習と相性がよく、現代の生成AIや大規模言語モデル(LLM)の基盤として広く使われています。系列の各要素が互いにどれだけ参照すべきかを学習し、長距離依存を比較的扱いやすい点が特徴です。
Attentionは「どこを見るか」を学習する仕組みであり、入力のどの部分が出力に寄与するかを動的に重み付けします。これにより、固定長の状態に情報を押し込める必要が薄れ、文脈が長くても表現が崩れにくい設計になっています。さらに並列化により学習効率が上がりやすく、スケール拡大と結びつきながら性能が伸びてきました。その一方で、計算資源依存や安全性などの新しい課題も同時に顕在化し、構造理解と運用設計の重要性が増しています。
5. 人工ニューラルネットワークの限界と課題
人工ニューラルネットワークは強力な関数近似器である一方、構造的・運用的な制約を抱えています。性能だけを見ると「スケールすれば良くなる」ように見える場面もありますが、実運用では分布シフト、説明責任、資源制約、安全性といった制約が前面に出ます。ここでは技術的観点から、どこに脆弱性があり、どのように問題が顕在化しやすいかを整理します。限界を知ることは悲観ではなく、適用範囲と設計の優先順位を誤らないための前提になります。
5.1 データ依存構造がもたらす脆弱性
ANNは基本的にデータからしか学習できず、データに含まれない分布や因果構造を自動的に獲得するわけではありません。言い換えると、学習は観測データの統計構造(相関)に強く依存し、分布が変わると性能が崩れやすいです。偏ったデータは偏ったモデルを生み、外挿(extrapolation)に弱いという性質は、単なる理論ではなく、プロダクションで頻繁に問題化します。特に現場で厄介なのは、訓練時には高精度に見えるのに、本番環境で入力分布が微妙に変わった瞬間、予測が不安定化するケースです。
代表的なリスクは、分布シフト、データリーク、過学習に集約されます。これらは独立した問題というより、データ設計・評価設計・運用設計の弱点が連鎖して起きる形が多いです。
| 問題 | 発生原因 | 結果 |
|---|---|---|
| 過学習 | データ不足、容量過多、正則化不足 | 汎化性能低下、検証と本番の乖離 |
| バイアス | 偏ったサンプル、収集経路の偏り | 不公平な出力、特定集団への性能劣化 |
| 分布変化 | 実環境との差、季節性・仕様変更 | 推論精度崩壊、監視コスト増大 |
5.2 計算資源への過度な依存
大規模化により性能が向上する局面は確かに存在しますが、その裏側で計算コストは急激に増えます。モデルが大きくなるほど、訓練に必要な計算量、メモリ、通信、電力、時間が増大し、運用の制約が強まります。研究段階では「回せば勝つ」戦略が成立しても、事業環境では推論コスト・レイテンシ・エネルギー制約・ハードウェア調達などがボトルネックになり、設計の選択肢が現実的に狭まります。結果として、性能向上が「構造理解」より「スケール拡大」に依存しやすい点が、技術的にも運用的にも課題になります。
計算資源コストとして現れやすい項目は次の通りです。
・GPU/TPU使用:アクセラレータ依存が強まり、供給制約の影響を受けやすくなります。
・メモリ消費:バッチサイズや系列長、モデル幅の制約が設計に跳ね返ります。
・電力消費:学習・推論の継続運用でコストと環境負荷が顕在化します。
・学習時間:反復実験の速度が落ち、改善サイクルが遅延します。
ANNの進化が計算資源の進化と結びついてきたのは事実ですが、だからこそ「どこまでスケールで押し、どこから構造で効率化するか」という設計判断が、実務では戦略になります。
5.3 ブラックボックス性と説明困難性
ANNは高次元パラメータ空間で最適化された結果として振る舞うため、内部で何が起きているかを完全に説明することは一般に難しいです。層を重ねた非線形変換の合成は、入力の微小変化がどのように出力へ影響するかを直観的に追いにくくし、意思決定の根拠を「人間に理解できる言葉」で提示することを困難にします。これは単なる可視化不足ではなく、表現が高次元で分散し、単一の特徴に意味を割り当てにくいという構造的な理由があります。説明が求められる領域では、性能が高いことだけでは採用条件を満たせないケースが増えます。
| 観点 | 課題 |
|---|---|
| 医療 | 判断根拠の提示が要求され、説明責任が重い |
| 金融 | 規制対応・監査対応で説明可能性が前提になる |
| 法律 | 不利益処分の根拠提示など、説明責任が制度的に要求される |
Explainable AI(XAI)はこの問題への主要なアプローチですが、XAI自体も「説明の近似」であることが多く、説明と忠実性(モデルの真の理由)のギャップが論点になり得ます。
5.4 因果理解の欠如
ANNは基本的に相関構造を学習する枠組みであり、因果関係を自動的に同定するようには設計されていません。相関は「一緒に変動する」関係で、因果は「原因と結果」の関係です。観測データから相関は強く推定できますが、因果は介入や反事実を含む追加の仮定やデータが必要になることが一般的です。ANNはパターン認識には強い一方、因果推論の要件(介入の効果推定、反事実推論、因果グラフの整合)を満たす仕組みを標準では持たないため、外挿や分布変化に弱いという性質とも結びつきます。
この制約は、モデルの欠点というより適用領域の見極めに直結します。たとえば「相関が強い環境での予測」は高精度でも、「介入したらどうなるか」「条件が変わったら何が原因で変わるか」といった問いに対しては、同じ精度保証を期待できません。相関で解ける問題と因果が必要な問題を分け、必要なら因果推論の枠組みや追加データ設計を併用する、というのが現実的な設計姿勢になります。
5.5 汎化能力と安全性の問題
訓練データでは高精度でも、未知環境では予測不能な振る舞いをする場合がある点は、ANNの運用上の重大リスクです。わずかな入力変化に過敏に反応する、意図しないショートカット特徴へ依存する、敵対的攻撃で誤分類する、といった現象は、単なるバグではなく、学習が統計的にもっとも「楽な説明」を選びやすいことに起因します。安全性を保証するには、学習・評価・監視・フェイルセーフまで含めた設計が必要ですが、入力空間が高次元であるほど、完全検証が難しくなります。
主なリスクは次の通りです。
・敵対的攻撃(Adversarial Attack):人間には同一に見える入力変化で予測を崩されます。
・小さな入力変化への過敏反応:分布境界付近で不安定になり、運用が揺れます。
・予期せぬ誤分類:ショートカット特徴やデータリークに依存して崩れます。
安全性保証が難しい、完全検証が実質不可能、失敗時の責任所在が曖昧になりやすい、という現実は、モデルの性能だけでは解消できません。したがって、ANNの適用では「どの失敗が許容できないか」を先に定義し、監視と介入設計(閾値、拒否、人的レビュー、フォールバック)を含めて運用することが、技術的にも組織的にも重要になります。
まとめ
ANNの強みは、非線形変換を層として積み重ね、入力空間では捉えにくい構造を表現空間で再配置できる点にあります。ただし、その強みは同時に脆弱性でもあり、データ偏り・分布変化・最適化不安定・計算資源制約・説明困難性といった形で、運用リスクとして顕在化します。本番環境では、精度低下が見える前に、予測分布の揺れ、閾値設計の不安定化、推論遅延、監査対応の詰まりといった症状として先に現れやすく、モデル内部の前提が共有されていないほど復旧と改善が重くなります。したがって、層の責務、出力の意味づけ、評価指標と停止条件、監視と介入設計までを一体として設計し、変更に耐える説明可能性を作ることが、性能を事業価値へ翻訳するための現実的な手段になります。
ANNは「高精度モデル」を作る技術というより、「不確実性がある環境で、統計的判断を継続的に最適化する仕組み」を構築する技術として捉えるほうが実務に合います。相関で解ける問題と因果が必要な問題を峻別し、許容できない失敗を先に定義し、人的レビューやフォールバックを含む運用回路を埋め込むことで、性能は安定した意思決定へ変換されやすくなります。さらに、データ収集・ラベル設計・評価設計・監視の更新が一つのループとして回るほど、分布変化に対する耐性が上がり、改善が一過性の成功体験で終わりにくくなります。ANNの限界を理解することは適用を狭めるためでなく、設計の優先順位を誤らず、長期の保守性と安全性を確保しながら運用コストを最小化するための前提条件だと言えます。








