 EN
EN JP
JP KR
KR
LangChainとLlamaIndex|RAG設計における違いと選び方
大規模言語モデル(LLM)の進化によって、企業や研究機関における生成AI活用の幅はかつてないほど広がりました。しかし、LLMをそのまま利用するだけでは、現実のビジネス要件を満たすには不十分な場面も多く存在します。例えば、最新情報を反映させたい場合や、社内のナレッジを踏まえた応答が必要な場合、LLM単独では対応できません。また、長文処理や複雑な文脈理解においては、知識の欠落や幻覚(hallucination)が課題になります。
そこで登場するのが RAG(Retrieval-Augmented Generation) です。RAGは「検索」と「生成」を組み合わせるアプローチであり、外部データを取得してLLMに統合することで、より信頼性の高い応答を生み出します。この設計は、社内情報検索、FAQ自動応答、法務文書レビュー、研究支援など、多様な分野で注目を集めています。
本記事では、そのRAGを支える代表的な二つのフレームワーク LangChain と LlamaIndex を比較します。本記事では両者の設計思想やアーキテクチャ、強みと弱みを整理し、プロジェクトに応じた最適な選択の仕方を解説します。また、実務での適用を見据えたアイデアや応用のヒントも盛り込み、読者が自分のユースケースに合わせて戦略的に判断できるように導きます。
1. LangChainとは?
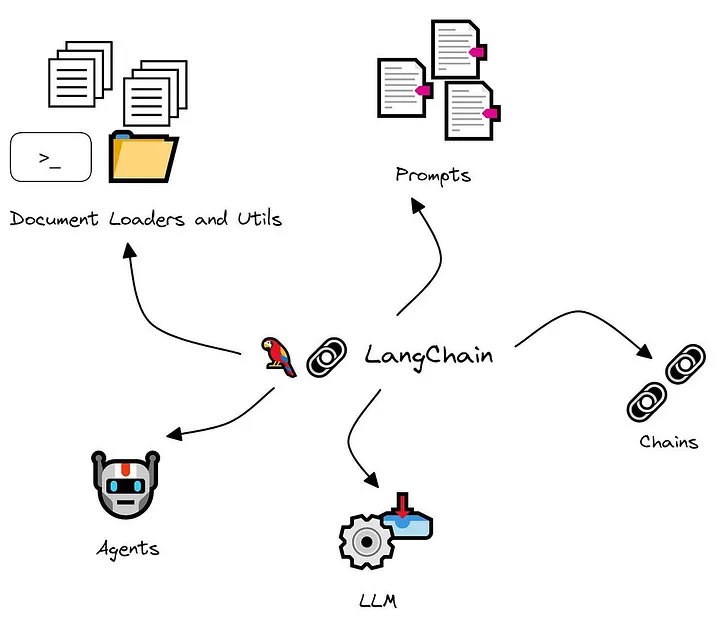
LangChainは、生成AIを活用したアプリケーションを開発するためのフレームワークです。2022年に登場し、瞬く間に世界中の開発者や企業に広がりました。その本質は「LLMを中心に据え、複雑な処理を統合的に制御する仕組み」です。
従来、LLMを単独で呼び出すと、単発の応答しか得られず、実務に直結させるには不便でした。LangChainはそこに「チェーン」という概念を導入し、タスクを段階的に処理できるようにしました。さらに「エージェント」を通じて、LLMが状況に応じて最適なツールを選びながら動的にタスクを進めることも可能です。
この仕組みによって、LangChainは単なるAPIラッパーを超え、業務自動化や知識統合を可能にする「知能的な制御フレームワーク」として定着しています。
1.1 特徴
LangChainの特徴を表にまとめると、全体像がより理解しやすくなります。
特徴 | 説明 |
チェーン | タスクを分解・連結し、段階的に実行可能 |
エージェント | LLMがツールを選択し、状況に応じて進行 |
モジュール統合 | APIやDB、外部クラウドサービスと柔軟に接続 |
プロンプト管理 | テンプレート化により一貫性あるプロンプト設計が可能 |
メモリ機能 | 対話履歴を保持し、長期的な文脈理解を実現 |
評価ツール | 実行のモニタリングと改善の仕組みを備える |
ロギング | 各処理を追跡できるため、監査性・再現性が高い |
エコシステム | 活発なコミュニティと豊富な拡張パッケージ |
これらの特徴が組み合わさることで、LangChainは「アプリ全体の頭脳」として機能します。
1.2 メリットと制約
LangChainを導入する際の利点と課題を整理すると次のようになります。
メリット | 制約 |
柔軟なワークフロー構築が可能 | 学習曲線が急で初心者には難しい |
多様な外部サービスと統合できる | 過剰設計による冗長化のリスク |
エージェントで動的制御が可能 | 複雑化によりオーバーヘッドが発生 |
コミュニティとプラグインが豊富 | 本格導入には高いエンジニアリング力が必要 |
プロンプト管理・メモリ機能で高度な応答 | 設定が複雑になりやすい |
モニタリングやログで改善が容易 | 運用コストが高い場合がある |
LangChainは「力強いが扱いが難しい」という性質を持ち、スキルとリソースのあるチーム向けです。
2. LlamaIndexとは?
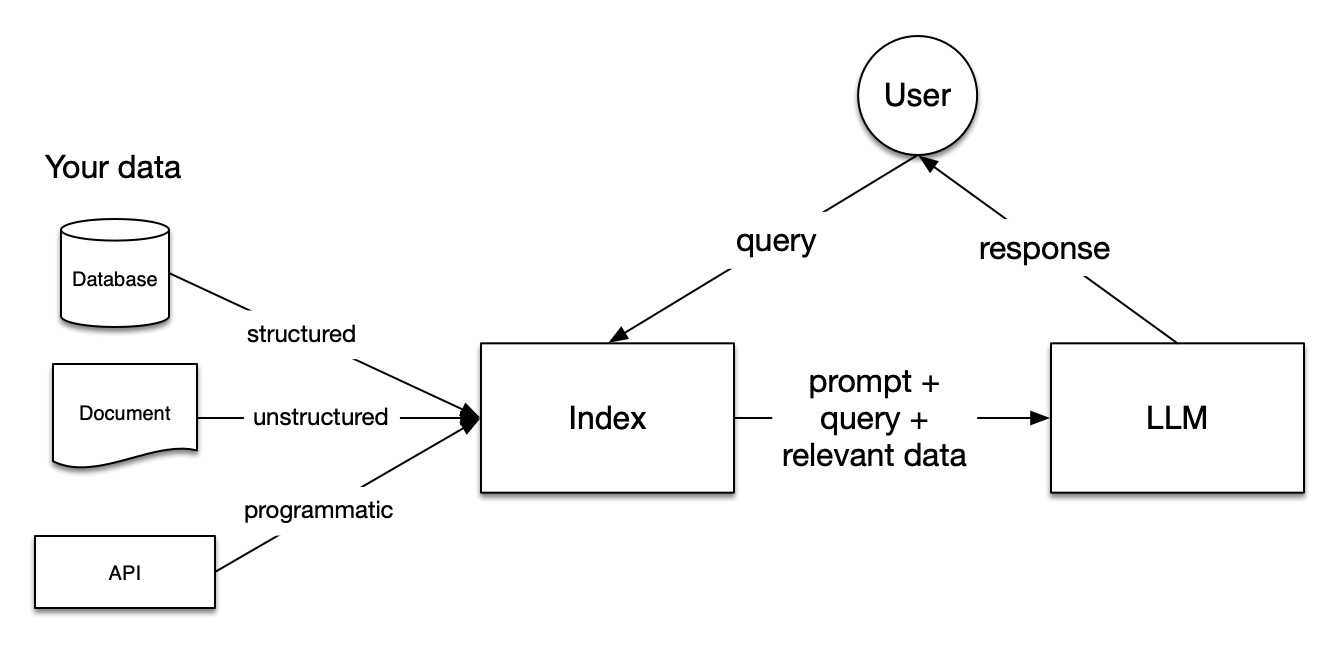
LlamaIndex(旧GPT Index)は、LLMに外部データを効率的に提供するためのインデックス基盤です。様々なデータソースを統合し、検索可能な形式に変換することで、LLMが必要とする知識をスムーズに利用できるようにします。
LangChainが「制御」に強みを持つのに対し、LlamaIndexは「データの整理と検索効率」に特化しています。これにより、シンプルかつ効率的にRAGを実装できるのが大きな魅力です。
2.1 特徴
LlamaIndexの特徴を幅広くまとめると以下の通りです。
特徴 | 説明 |
データコネクタ | PDF、Notion、Google Drive、SQLなどを統合 |
インデックス構造 | ツリー型、リスト型、グラフ型など柔軟に設計可能 |
クエリエンジン | 検索リクエストに応じて最適な結果を返却 |
キャッシュ機能 | 再利用性を高め、レスポンスを高速化 |
透明性 | データフローを可視化し、デバッグが容易 |
拡張性 | 検索アルゴリズムを切り替え可能 |
スケーラビリティ | 大量ドキュメントの取り扱いに強い |
シンプル設計 | 学習コストが低く、素早く導入可能 |
これにより、LlamaIndexは「データ基盤のハブ」としての地位を確立しています。
2.2 メリットと制約
メリット | 制約 |
データ接続・検索に特化して効率的 | エージェント制御は弱く、動的フローに不向き |
導入が容易で習得しやすい | アプリ全体の制御は苦手 |
多様なインデックス構造が選べる | LangChainに比べて統合力は弱い |
高速で精度の高い検索が可能 | 拡張的な業務プロセスには不足 |
デバッグや可視化が容易 | サービス連携の幅が狭い |
スケーラビリティが高い | 本番環境での運用には追加構築が必要 |
LlamaIndexは「シンプルで効率的なデータ処理ツール」として優れていますが、それ単体でアプリ全体を構築するのは難しいです。
3. LangChainとLlamaIndexの比較
LangChainとLlamaIndexは、ともにRAG(Retrieval Augmented Generation)を支える主要なフレームワークですが、その設計思想やアーキテクチャ、開発体験、そしてパフォーマンス面で異なる特徴を持っています。以下の表は、それぞれの違いを一望できるよう整理したものです。
項目 | LangChain | LlamaIndex |
中心概念 | 制御とオーケストレーション | データ接続と効率化 |
アーキテクチャ | チェーン+エージェントによる複雑なフロー制御 | インデックス+クエリエンジンによるシンプルな設計 |
主な役割 | システム全体の頭脳としてワークフローを管理 | 情報供給の基盤としてデータを整理・検索 |
強み | 柔軟性・多機能性・外部連携力 | シンプルさ・効率・安定した検索性能 |
弱み | 学習コストが高く、設計が複雑化しやすい | 制御力が限定的で複雑な自動化には不向き |
開発体験 | 高機能だが習得ハードルが高い | 習得が容易でデータ処理中心に適する |
パフォーマンス | 実装次第で精度や速度が変動、調整が必要 | 安定して高い検索精度と軽量高速な処理 |
スケーラビリティ | 大規模展開に対応可能だが調整必須 | データ集中型プロジェクトで安定性に強み |
適用性 | 業務プロセスの自動化や複雑な制御タスク | ナレッジ検索や文書整理中心の用途 |
LangChainは「複雑な制御や統合を要する大規模システム」に強く、LlamaIndexは「シンプルかつ効率的にデータを扱うプロジェクト」に適しています。両者は競合というより補完関係にあり、利用シーンに応じて適切に選択することで、RAGの効果を最大限に引き出すことができます。
4. LangChainとLlamaIndexの選び方の指針
LangChainとLlamaIndexを選ぶ基準は、プロジェクトの目的・規模・リソースに大きく依存します。
小規模なPoCや迅速な検証フェーズでは、学習コストが低く導入が簡単なLlamaIndexが適しています。例えば「社内FAQ検索」や「特定ドキュメントの検索補助」など、明確な範囲の中でスピーディに試したい場合です。
一方、複雑な業務自動化や複数システムとの連携が必要なプロジェクトではLangChainが有効です。特に「問い合わせ対応+外部API接続+レポート生成」といった一連のフローを自動化するようなケースでは、エージェント制御が大きな力を発揮します。
適用アイデア
5. LangChainとLlamaIndexの活用アイデア
LangChainとLlamaIndexは、それぞれ単独でも有効に機能しますが、実際のプロジェクトでは両者を組み合わせることで相乗効果を発揮する場面が多くあります。以下では、いくつかの活用アイデアを段落ごとに解説し、必要に応じて表を用いて整理します。
5.1 ナレッジ検索システム
企業や組織における膨大な文書資産は、そのままでは活用が難しい場合が多いです。LlamaIndexを利用することで、PDF、Word、スプレッドシートなどをインデックス化し、検索可能な形に整理できます。その検索結果をLangChainが受け取り、要約・翻訳・分類といった追加処理を行うことで、単なる検索以上の「知識活用プラットフォーム」として機能します。
役割分担 | LlamaIndex | LangChain |
データ処理 | 文書のインデックス化、検索最適化 | - |
応答生成 | - | 要約、翻訳、分類などの加工 |
利用者体験 | 基盤的な検索の提供 | 意図に沿った応答で満足度向上 |
5.2 顧客サポートAI
カスタマーサポートの現場では、FAQやマニュアルを迅速に検索することが求められます。LlamaIndexでこれらの情報を整理すれば、正確な知識が常に参照可能です。その上でLangChainを活用すると、顧客の質問内容に応じた対話フローや複数システム連携を自動化でき、より人間らしいサポート体験を提供できます。
顧客サポートにおける応用の観点を整理すると以下の通りです。
観点 | LlamaIndexの役割 | LangChainの役割 |
知識基盤 | FAQ・マニュアルの検索 | - |
応答制御 | - | 会話フローやAPI連携の制御 |
効率性 | 検索時間短縮 | 自動化による工数削減 |
5.3 研究支援ツール
研究分野では、膨大な論文や資料から必要な情報を迅速に抽出することが大きな課題です。LlamaIndexは論文データベースを効率的にインデックス化し、検索性能を高めます。さらにLangChainを組み合わせれば、検索結果の要約、複数論文の比較、研究レビューの自動生成などを行うことができます。これにより、研究者は情報収集にかける時間を短縮し、より創造的な作業に集中できるようになります。
5.4 法務文書レビュー
契約書や規約など、法務関連の文書は複雑かつ膨大です。LlamaIndexを活用することで、大量の契約書を検索可能な形に整理できます。その結果をLangChainで処理し、リスク箇所の抽出や他契約との比較を行えば、レビュー作業の効率が大幅に向上します。
この活用を表にまとめると次のようになります。
フェーズ | LlamaIndexの貢献 | LangChainの貢献 |
情報整理 | 契約書の検索可能化 | - |
レビュー | - | リスク箇所の抽出・比較 |
効率化 | 文書管理の合理化 | 分析プロセスの自動化 |
5.5 マルチモーダル応用
将来的な応用として、テキスト以外のデータも扱うRAGシステムが考えられます。例えば音声を文字起こししたデータや、画像に付与された説明テキストをLlamaIndexで整理し、LangChainがそれらを統合的に制御することで、マルチモーダルな応用が可能となります。これは、次世代の顧客体験や新しい研究支援の形につながるでしょう。
6. まとめ
LangChainとLlamaIndexは、それぞれ異なる役割を担いながらRAG設計を支える存在です。LangChainはアプリケーション制御とワークフロー設計のフレームワークであり、LlamaIndexはデータ接続と検索効率化の基盤です。
両者は競合するものではなく、補完し合う関係にあります。プロジェクトの目的やチームのスキルセットを見極め、時に単独で、時に組み合わせて活用することで、より実用的で信頼性の高いRAGシステムを実現できます。
