 EN
EN JP
JP KR
KR
データエンジニアリングとは?経営戦略に直結する基盤構築の全体像
データエンジニアリングは、大量のデータを収集、処理、統合し、ビジネスに活用可能な形に変換するプロセスであり、データドリブンな経営戦略を実現するための基盤です。AI、機械学習、ビジネスインテリジェンス(BI)を活用して競争力を強化する企業にとって、信頼性の高いデータ基盤は不可欠です。このプロセスにより、企業は顧客データ、運用データ、市場データを統合し、迅速かつ正確な意思決定を可能にします。
この記事では、データエンジニアリングの定義、仕組み、プロセス、主要ツール、導入メリット、注意点、データガバナンス、リアルタイム処理、AI/ML統合を詳細に解説します。初心者から中級者までがデータエンジニアリングを理解し、実際のビジネスに活用できる知識を提供します。表を活用して情報を整理し、論理的で読みやすい構成で進めます。データドリブンな意思決定を加速させたい方は、ぜひ最後までご覧ください。
1. データエンジニアリングとは?

データエンジニアリングとは、データを収集、処理、保存、分析に適した形に変換するための技術的プロセスとインフラストラクチャの構築を指します。データサイエンスやBIの基盤となる高品質なデータを提供し、企業が迅速かつ正確な意思決定を行えるようにします。データエンジニアリングは、データパイプラインの設計、データウェアハウスの構築、データガバナンスの確保など、多岐にわたるタスクを包含します。
データエンジニアリングの目的は、データの「信頼性」「アクセス性」「スケーラビリティ」を確保することです。データエンジニアリングにより、異なるデータソース(POSシステム、CRM、ウェブサイト)を統合し、分析可能な形式に変換することで、経営陣は正確なデータに基づいて戦略を立案でき、ビジネスの成果を最大化できます。以下の表で、データエンジニアリングの主要な目標を整理します。
目標 | 説明 |
| 信頼性 | データの正確性と一貫性を確保し、誤った分析を防ぐ |
| アクセス性 | 必要なユーザーが迅速にデータにアクセスできる環境を提供 |
| スケーラビリティ | データ量や処理ニーズの増加に対応可能なインフラを構築 |
2. データエンジニアリングの仕組みとプロセス
データエンジニアリングは、データのライフサイクルを管理するための体系的なプロセスです。ここでは、その主要プロセスと仕組みを詳細に分析します。
2.1 データエンジニアリングの主要プロセス
データエンジニアリングは、データの収集から提供までをカバーする複数のプロセスで構成されます。以下の表で、主要プロセスを整理します。
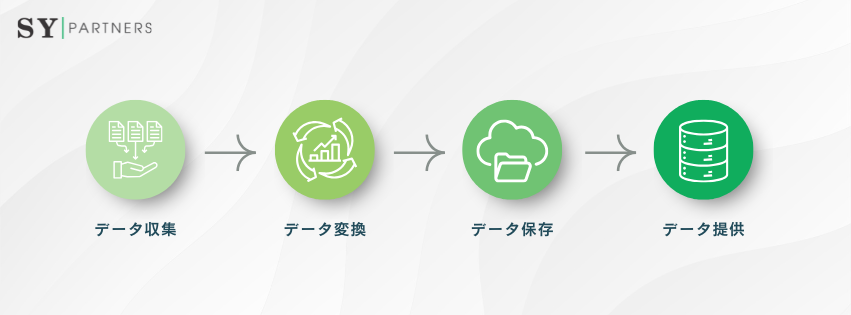
プロセス | 説明 |
| データ収集 | データベース、API、ログファイル、IoTデバイスなどからデータを取得 |
| データ変換 | ETL(抽出、変換、ロード)またはELTプロセスでデータをクレンジング・統合 |
| データ保存 | データウェアハウスやデータレイクにデータを格納 |
| データ提供 | BIツール、AIモデル、ダッシュボードにデータを供給 |
これらのプロセスは、データパイプラインとして統合され、効率的かつスケーラブルなデータフローを実現します。顧客データをリアルタイムで処理し、ダッシュボードで可視化する場合、データ収集から提供までの一連のプロセスがシームレスに連携する必要があります。
2.2 データパイプラインの構造
データパイプラインは、データエンジニアリングの中核であり、データの収集から提供までを自動化します。
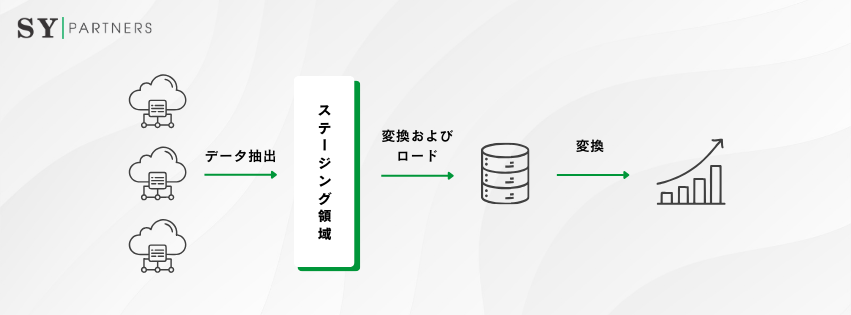
以下の表で、データパイプラインの構造を整理します。
コンポーネント | 説明 |
| データソース | 内部データ(CRM、ERP)や外部データ(API、IoTデバイス)を取得 |
| 抽出(Extract) | データをソースから抽出 |
| 変換(Transform) | データをクレンジング、標準化、統合して分析可能な形式に変換 |
| ロード(Load) | データウェアハウスやデータレイクにデータを保存 |
| オーケストレーション | データフローをスケジュールし、依存関係を管理(例:Apache Airflow) |
データパイプラインは、クラウドネイティブなツール(例:AWS Glue、Google Dataflow)を使用することで、スケーラビリティとリアルタイム性を強化できます。ストリーミングデータを処理する場合、Apache Kafkaを活用してリアルタイムデータパイプラインを構築し、遅延を最小化できます。
以下の表で、ETLとELTの違いを補足します。
項目 | ETL | ELT |
| 処理順序 | 抽出→変換→ロード | 抽出→ロード→変換 |
| データ処理場所 | 専用サーバーやミドルウェアで変換 | データウェアハウス内で変換 |
| ユースケース | 構造化データの処理に適する | 大規模・非構造化データの処理に適する |
3. データエンジニアリングの主要ツール
データエンジニアリングには、データ収集、処理、保存、分析を効率化するための多様なツールが使用されます。以下の表で、主要ツールをカテゴリ別に整理します。
カテゴリ | ツール | 特徴 |
| データ収集 | Apache Kafka, AWS Kinesis | リアルタイムストリーミングデータの収集 |
| データ変換 | Apache Spark, dbt | 大規模データの処理、ETL/ELTプロセスの自動化 |
| データ保存 | Snowflake, Google BigQuery | クラウドベースのデータウェアハウス、スケーラブルなデータ保存 |
| オーケストレーション | Apache Airflow, Prefect | データパイプラインのスケジュール管理と依存関係の制御 |
| データ統合 | AWS Glue, Talend | 複数のデータソースを統合、ETLプロセスを効率化 |
これらのツールは、クラウド環境(AWS、Google Cloud、Azure)との統合が進んでおり、マルチクラウド対応やサーバーレスアーキテクチャを活用することで、柔軟性と効率性が向上します。
Apache Kafkaはリアルタイムデータストリーミングに最適であり、SnowflakeはSQLベースの高速分析を可能にします。Apache Airflowは、複雑なデータパイプラインのスケジュール管理に強みを持ち、依存関係を視覚化してエラー管理を効率化します。
以下の表で、主要ツールの適用シナリオを補足します。
ツール | 適用シナリオ |
| Apache Kafka | IoTデバイスからのデータ収集、リアルタイム異常検知 |
| Snowflake | 大規模データ分析、BIダッシュボードのデータ提供 |
| Apache Airflow | 複雑なデータパイプラインのスケジュール管理 |
4. データエンジニアリングの導入メリット
データエンジニアリングを導入することで、企業はデータドリブンな意思決定を加速し、競争力を強化できます。以下に、主要なメリットを詳細に分析します。

4.1 データの信頼性と品質の向上
データエンジニアリングは、データの正確性と一貫性を確保します。以下の表で、信頼性向上のポイントを整理します。
ポイント | 説明 |
| データクレンジング | 不完全なデータ、重複、エラーを除去し、データの整合性を確保 |
| データ標準化 | 異なるソースのデータを統一フォーマットに変換、分析の一貫性を確保 |
| データ検証 | 自動検証プロセスでエラーを検出し、データ品質を維持 |
高品質なデータは、AIモデルやBIダッシュボードの精度を向上させ、誤った意思決定のリスクを軽減します。売上データをクレンジングすることで、正確な業績予測や在庫管理が可能になり、ビジネス成果が向上します。
4.2 リアルタイム分析の実現
リアルタイムデータ処理は、迅速な意思決定を可能にします。以下の表で、リアルタイム分析のポイントを整理します。
ポイント | 説明 |
| ストリーミング処理 | Apache KafkaやAWS Kinesisでリアルタイムデータを取り込み |
| 高速クエリ | SnowflakeやBigQueryで大規模データの高速分析 |
| 自動化パイプライン | データフローを自動化し、遅延を最小化 |
顧客の行動データをリアルタイムで分析し、パーソナライズされたレコメンドやキャンペーンを展開することで、顧客満足度と売上が向上します。
4.3 スケーラビリティと柔軟性
データエンジニアリングは、データ量の増加や新たな要件に対応するスケーラブルな基盤を提供します。以下の表で、スケーラビリティのポイントを整理します。
ポイント | 説明 |
| クラウドネイティブ | AWS、Google Cloud、Azureでスケーラブルなインフラを構築 |
| モジュラー設計 | データパイプラインをモジュール化し、新たなデータソースを容易に追加 |
| コスト最適化 | クラウドの従量課金モデルを活用し、コストを効率化 |
クラウドベースのデータ基盤は、データ量の急増にも対応し、ビジネスの成長を支えます。新たなデータソース(例:SNSデータ)を追加する場合、モジュラー設計により既存のパイプラインに簡単に統合できます。
4.4 経営戦略への貢献
データエンジニアリングは、データドリブンな経営戦略を支えます。以下の表で、経営戦略への貢献を整理します。
ポイント | 説明 |
| 迅速な意思決定 | 高品質なデータで戦略立案を加速 |
| パーソナライズ | 顧客データを活用し、個別最適化されたマーケティングを実現 |
| 競争力強化 | データ分析を活用し、市場動向や顧客ニーズを先取り |
顧客データを統合し、BIツールで可視化することで、経営陣は市場動向を迅速に把握し、戦略を調整できます。これにより、競合他社に対する優位性を確立できます。
5. データエンジニアリング導入時の注意点
データエンジニアリングを効果的に導入するには、以下の注意点を考慮する必要があります。各ポイントを詳細に分析します。

5.1 データガバナンスの確立
データガバナンスは、データの信頼性とセキュリティを確保するための枠組みです。以下の表で、データガバナンスのポイントを整理します。
ポイント | 説明 |
| データポリシー | データのアクセス権限や使用ルールを定義 |
| コンプライアンス | GDPRやCCPAなど、データ保護規制への対応 |
| 監査トレイル | データの変更履歴を追跡し、透明性を確保 |
データガバナンスを怠ると、データ漏洩や規制違反のリスクが高まります。GDPR準拠のデータ処理を徹底することで、罰金を回避し、顧客信頼を維持できます。
5.2 コスト管理
データエンジニアリングは、クラウドコストの増大を招く可能性があります。以下の表で、コスト管理のポイントを整理します。
ポイント | 説明 |
| リソース最適化 | 不要なデータ処理やストレージを削減 |
| 自動スケーリング | クラウドのリソースを需要に応じて調整 |
| コストモニタリング | AWS Cost Explorerなどでコストを追跡 |
コスト管理を徹底することで、データ基盤の持続可能性を高められます。不要なデータパイプラインを停止することで、クラウドコストを最適化できます。
5.3 技術的スキルの確保
データエンジニアリングには高度なスキルが必要です。以下の表で、必要なスキルを整理します。
スキル | 説明 |
| プログラミング | Python、SQL、Scalaなどでのデータ処理 |
| クラウド技術 | AWS、Google Cloud、Azureのデータサービス活用 |
| データモデリング | データウェアハウスやデータレイクのスキーマ設計 |
スキルの不足は、プロジェクトの遅延や品質低下を招くため、継続的なトレーニングや専門家の雇用が重要です。PythonとSQLを習得することで、データパイプラインの構築や最適化が効率化します。
5.4 データセキュリティ
データセキュリティは、データ基盤の信頼性を確保するために不可欠です。以下の表で、セキュリティ対策を整理します。
対策 | 説明 |
| データ暗号化 | 保存データと転送データの暗号化(例:AES-256、TLS) |
| アクセス制御 | IAM(Identity and Access Management)でアクセスを制限 |
| 監視と検知 | 異常検知ツール(例:AWS CloudTrail)でセキュリティインシデントを監視 |
セキュリティ対策を徹底することで、データ漏洩や不正アクセスのリスクを軽減できます。IAMを活用して、データへのアクセスを最小権限原則に基づいて制限できます。
6. データガバナンスとデータ品質管理
データガバナンスとデータ品質管理は、データエンジニアリングの成功に不可欠です。以下の表で、データガバナンスの主要な構成要素を整理します。
構成要素 | 説明 |
| データカタログ | データ資産を一元管理し、検索性を向上(例:AWS Glue Data Catalog) |
| メタデータ管理 | データの出自や構造を記録し、トレーサビリティを確保 |
| ポリシー管理 | データの使用ルールやプライバシー保護を定義 |
データガバナンスを強化することで、データの信頼性とコンプライアンスが向上します。データカタログを活用することで、データサイエンティストが迅速に必要なデータを見つけ、分析を効率化できます。以下の表で、データ品質管理の具体的な手法を補足します。
手法 | 説明 |
| データプロファイリング | データの統計的特性を分析し、異常や欠損を検出 |
| 自動検証 | ルールベースのチェックでデータエラーを自動検出 |
| 品質監視 | データ品質メトリクスを継続的に監視し、問題を早期発見 |
データ品質管理では、自動化された検証プロセスを導入することで、エラーを早期に検出し、データの一貫性を維持できます。
7. リアルタイムデータ処理の設計
リアルタイムデータ処理は、データエンジニアリングの重要な側面であり、迅速な意思決定を支えます。以下の表で、リアルタイム処理の設計ポイントを整理します。
指定の3ポイント(ストリーミングアーキテクチャ、イベント駆動処理、低遅延クエリ)に4つのポイント(データパーティショニング、ストリームバッチ統合、モニタリングとアラート、データスキーマ管理)を追加し、合計7ポイントで構成します。
ポイント | 説明 |
| ストリーミングアーキテクチャ | Apache KafkaやAWS Kinesisでリアルタイムデータを取り込み |
| イベント駆動処理 | サーバーレスアーキテクチャ(例:AWS Lambda)でイベントに応じた処理 |
| 低遅延クエリ | データウェアハウス(例:Snowflake)で高速クエリを実行 |
| データパーティショニング | 大規模データを分割し、処理速度とスケーラビリティを向上 |
| ストリームバッチ統合 | ストリーミングとバッチ処理を統合(例:Apache Flink)で柔軟な処理を実現 |
| モニタリングとアラート | リアルタイム処理の障害を検知(例:AWS CloudWatch)で安定性を確保 |
| データスキーマ管理 | スキーマ進化を管理し、データ構造の変更に対応 |
リアルタイム処理を導入することで、ビジネスは市場の変化に迅速に対応できます。顧客の閲覧データをリアルタイムで処理し、動的な価格設定やレコメンドを展開することで、売上を最大化できます。
データパーティショニングは、データウェアハウスでの並列処理を効率化し、ストリームバッチ統合は一貫したデータフローを実現します。モニタリングとアラートは、障害を迅速に検出し、システムの安定性を確保します。データスキーマ管理は、データソースの変更に柔軟に対応し、整合性を維持します。以下の表で、リアルタイム処理の課題と解決策を補足します。
課題 | 解決策 |
| データ遅延 | ストリーミングアーキテクチャを最適化(例:Kafkaのトピック分割) |
| リソース過負荷 | 自動スケーリングを導入し、負荷に応じたリソース割り当て |
| データ不整合 | スキーマ管理と検証プロセスを導入 |
8. データエンジニアリングとAI/ML統合
データエンジニアリングは、AIや機械学習(ML)の成功に不可欠なデータ基盤を提供します。以下の表で、AI/ML統合のポイントを整理します。
ポイント | 説明 |
| データ準備 | クレンジング、標準化、特徴量エンジニアリングでMLモデル用のデータを作成 |
| パイプライン自動化 | MLパイプライン(例:SageMaker、Databricks)でデータ処理を自動化 |
| モデルデプロイ | リアルタイム推論やバッチ推論にデータを供給 |
AI/ML統合により、データエンジニアリングは予測分析やパーソナライズを強化します。顧客データを特徴量として処理し、MLモデルで需要予測を行うことで、在庫管理を最適化できます。
以下の表で、AI/ML統合の具体的なプロセスを補足します。
プロセス | 説明 |
| 特徴量エンジニアリング | ビジネスニーズに基づき、MLモデルに最適な特徴量を抽出・作成 |
| モデルトレーニング | データパイプラインから供給されたデータでモデルを学習 |
| 推論パイプライン | リアルタイムまたはバッチ処理で予測結果を生成 |
パイプライン自動化は、モデルトレーニングとデプロイの効率を高め、ビジネス価値を迅速に実現します。
まとめ
データエンジニアリングは、データの収集、処理、保存、提供を通じて、データドリブンな経営戦略を支える基盤です。ETL/ELTプロセス、データパイプライン、クラウドネイティブなツールを活用することで、データの信頼性、リアルタイム性、スケーラビリティを実現します。データガバナンス、コスト管理、セキュリティ対策、AI/ML統合を徹底することで、データ基盤の効果を最大化できます。この記事を参考に、データエンジニアリングの基礎を理解し、ビジネスの競争力を強化してください。

