 EN
EN JP
JP KR
KR
A/Bテストのサンプルとは?実験精度を左右するデータ設計を解説
A/Bテストは、Webサイトやアプリ、LP、広告、メール、UI改善などで広く使われる実験手法です。AパターンとBパターンを比較し、どちらがより高い成果を出すのかを検証することで、感覚ではなくデータに基づいた意思決定が可能になります。
しかし、A/Bテストの結果は、どのようなサンプルを使うかによって大きく変わります。サンプル数が少なすぎると偶然の影響を強く受け、偏ったユーザーだけを対象にすると全体に適用できない結果になります。
特にコンバージョン率やクリック率の改善を目的とする場合、サンプル設計は実験精度を左右する重要な要素です。サンプルサイズ、ランダム分割、セグメント、実験期間、統計的有意性を正しく理解しなければ、A/Bテストの結果を誤って解釈してしまう可能性があります。
この記事では、A/Bテストにおけるサンプルの基本、サンプルサイズの考え方、サンプル不足やサンプル過多の問題、ランダムサンプリング、偏り、UX分析との関係まで体系的に解説します。
1. A/Bテストにおけるサンプルとは?
A/Bテストにおけるサンプルとは、実験に参加するユーザーやセッション、アクセス、クリック、コンバージョンなどのデータを指します。たとえば、LPのボタン色を比較するA/Bテストでは、Aパターンを見たユーザーとBパターンを見たユーザーがサンプルになります。
サンプルは、A/Bテストの結果を支える基礎データです。どのようなユーザーが含まれているか、どれくらいの人数がいるか、どのように分割されたかによって、テスト結果の信頼性は大きく変わります。
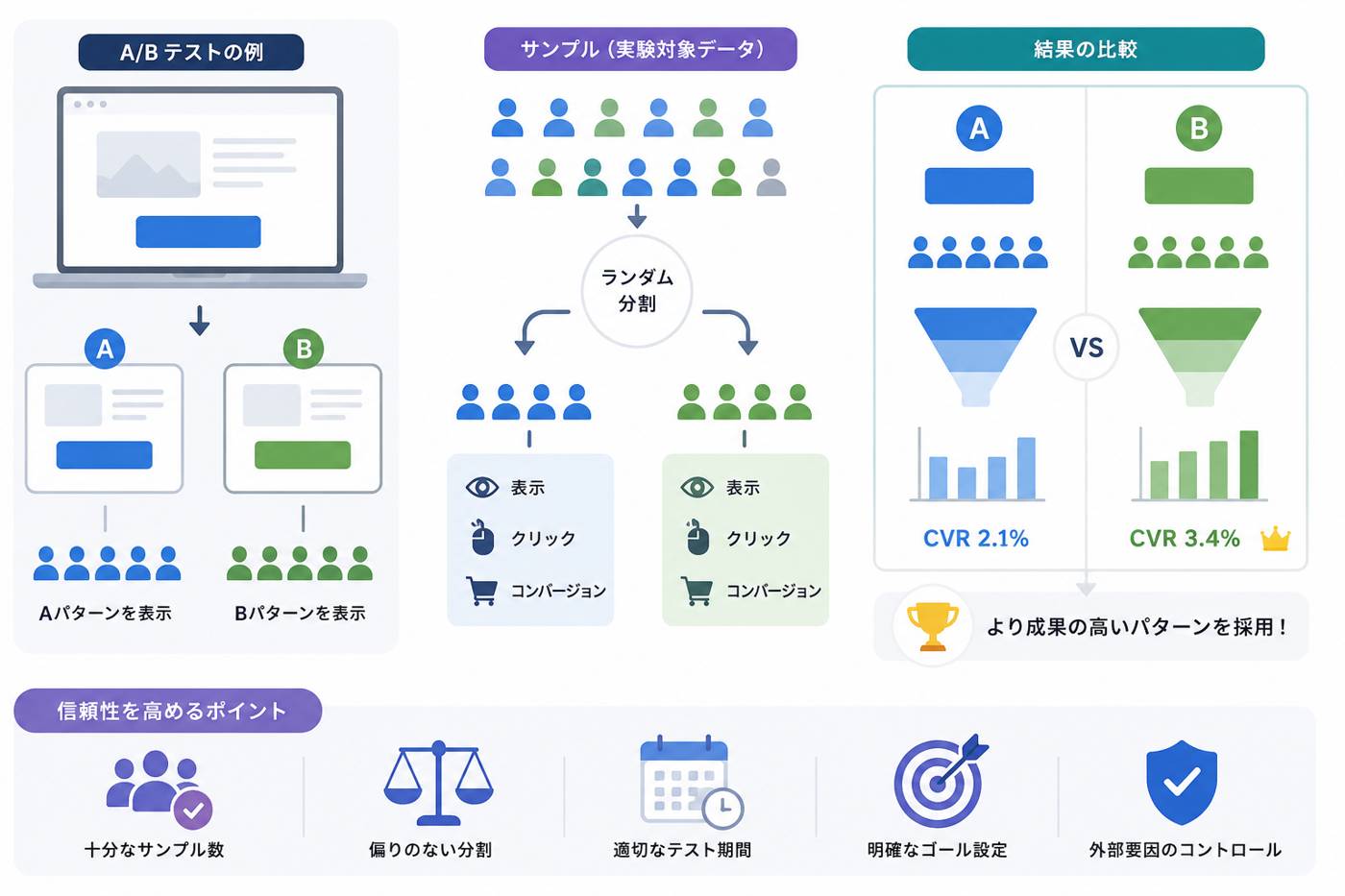
A/Bテストにおけるサンプルの特徴を整理すると、以下のようになります。
| 項目 | 内容 |
|---|---|
| 意味 | A/Bテストに参加する実験対象データ |
| 対象 | ユーザー、セッション、クリック、CVなど |
| 目的 | AパターンとBパターンを比較検証する |
| 重要性 | 統計精度や意思決定の信頼性を左右する |
| 注意点 | サンプル数、偏り、分割方法、期間設計が重要 |
1.1 A/B比較に参加するユーザー群
A/Bテストのサンプルは、実験対象となるユーザー群を意味します。たとえば、あるWebページの見出しをA案とB案で比較する場合、それぞれの見出しを見たユーザーがサンプルとして扱われます。
このユーザー群が適切に分割されていないと、テスト結果は信頼できなくなります。A案に新規ユーザーが多く、B案に既存ユーザーが多い場合、結果の差がデザイン変更によるものなのか、ユーザー属性の違いによるものなのか判断できません。
1.2 実験結果を支える基礎データ
A/Bテストの結果は、サンプルから得られた行動データによって決まります。クリック率、コンバージョン率、購入率、滞在時間、離脱率などは、すべてサンプル内のユーザー行動から計算されます。
そのため、サンプルの品質が低いと、どれだけ高度な分析を行っても正しい結論にはつながりません。A/Bテストでは、実験内容だけでなく、どのデータを使って判断するのかを慎重に設計する必要があります。
1.3 統計的信頼性を決める要素
サンプルは、A/Bテストの統計的信頼性を決める重要な要素です。サンプル数が十分であれば、偶然によるブレが小さくなり、実験結果をより安定して解釈できます。
一方で、サンプル数が少ない場合、たまたま数人が購入しただけでB案が良く見えることがあります。統計的に信頼できるA/Bテストを行うには、十分なサンプル数と適切な分割が不可欠です。
2. サンプルサイズとは?
サンプルサイズとは、A/Bテストで使用するデータ量のことです。通常は、各パターンに割り当てられたユーザー数、セッション数、またはコンバージョン数を指します。
サンプルサイズは、A/Bテストの精度に大きく影響します。少なすぎると偶然の影響を受けやすくなり、多すぎると小さな差でも統計的に有意になりやすくなります。
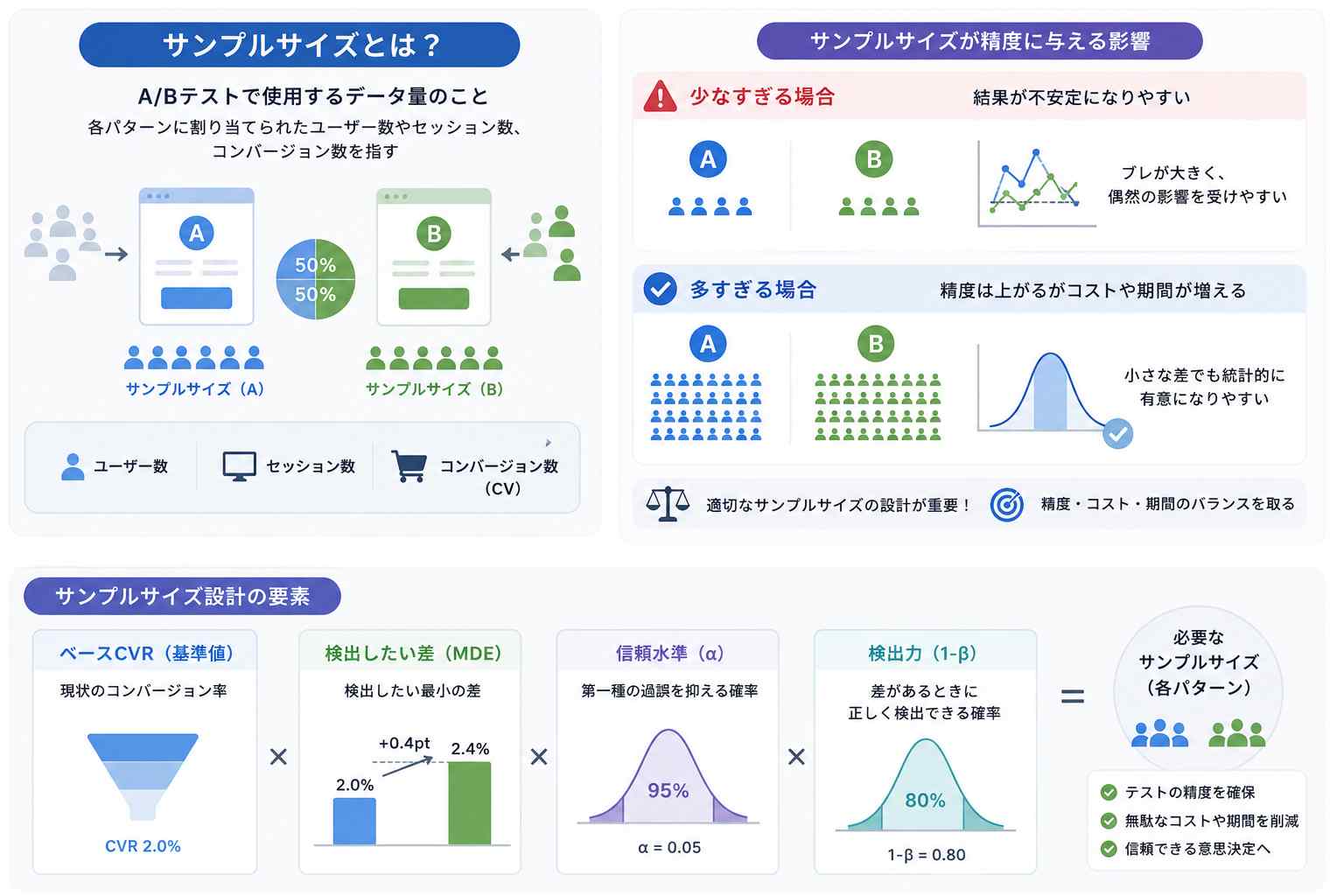
サンプルサイズの基本的な考え方を整理すると、以下のようになります。
| 項目 | 内容 |
|---|---|
| 意味 | A/Bテストで使うデータ量 |
| 単位 | ユーザー数、セッション数、CV数など |
| 少ない場合 | 結果が不安定になりやすい |
| 多い場合 | 精度は上がるがコストや期間が増える |
| 設計要素 | ベースCVR、検出したい差、信頼水準、検出力 |
2.1 何人分のデータを使うか
サンプルサイズとは、簡単にいえば「何人分のデータで判断するか」という考え方です。A/Bテストでは、AパターンとBパターンそれぞれに十分な人数を割り当てる必要があります。
たとえば、A案を100人、B案を100人だけに見せた場合、数件のコンバージョン差だけで結果が大きく変わる可能性があります。判断に使う人数が少ないほど、結果は偶然に左右されやすくなります。
2.2 大きいほど精度が上がる
一般的に、サンプルサイズが大きくなるほど、A/Bテストの結果は安定しやすくなります。多くのユーザー行動を集めることで、一部の偶然や外れ値の影響を小さくできるためです。
ただし、サンプルサイズが大きければ必ず良いというわけではありません。非常に大きなサンプルでは、実務上ほとんど意味のない小さな差でも統計的に有意になることがあるため、ビジネス上の意味も合わせて判断する必要があります。
2.3 少ないと誤判定が増える
サンプルサイズが少ないと、A/Bテストの誤判定が増えます。本当は差がないのに差があるように見えたり、逆に本当は効果があるのに検出できなかったりする可能性があります。
特にコンバージョン率が低いサービスでは、十分なコンバージョン数を集めるまでに時間がかかります。サンプル数が少ない段階で判断すると、施策の効果を誤って評価する危険があります。
3. なぜサンプル数が重要なのか
A/Bテストでサンプル数が重要なのは、実験結果の信頼性を高めるためです。A/Bテストはユーザー行動を比較する手法ですが、ユーザー行動には常に偶然やばらつきが含まれます。
十分なサンプル数があれば、偶然の影響を小さくし、施策による本当の差を見つけやすくなります。以下に、サンプル数が重要な理由を整理します。
| 理由 | 内容 |
|---|---|
| 偶然の影響を減らす | 少数データによるブレを抑える |
| ノイズを小さくする | 外部要因や個別行動の影響を弱める |
| 有意差判定に必要 | 統計的な比較を成立させる |
| 判断の安定性を高める | 結果の再現性を上げる |
| 誤判定を防ぐ | 勝者の誤選択を減らす |
3.1 偶然の影響を減らすため
ユーザー行動には、必ず偶然の要素が含まれます。たまたま購買意欲の高いユーザーがBパターンに多く割り当てられれば、B案が優れているように見える可能性があります。
サンプル数が多ければ、このような偶然の偏りは平均化されやすくなります。少人数の結果ではなく、多くのユーザー行動をもとに判断することで、より信頼性の高い結論を出せます。
3.2 ノイズを小さくするため
A/Bテストの結果には、施策以外の要因も影響します。曜日、時間帯、広告流入、キャンペーン、季節性、競合の動きなど、さまざまなノイズがユーザー行動を変化させます。
サンプル数が少ないと、こうしたノイズの影響を強く受けます。十分なサンプルを集めることで、一時的な変動ではなく、より安定した傾向を把握しやすくなります。
3.3 有意差判定に必要
統計的有意差を判断するには、一定以上のサンプル数が必要です。サンプルが少なすぎると、A案とB案に差が見えても、それが偶然なのか本当の差なのかを判断しにくくなります。
有意差判定は、A/Bテストの結果を客観的に評価するための重要な手段です。ただし、有意差だけでなく、効果量やビジネス上の意味も合わせて確認することが大切です。
4. サンプル不足問題
サンプル不足とは、A/Bテストの判断に必要なデータ量が十分に集まっていない状態です。この状態で結果を判断すると、誤った勝者を選んだり、効果のある施策を見逃したりする可能性があります。
特にアクセス数が少ないサイトやCVRが低いサービスでは、サンプル不足が起こりやすくなります。サンプル不足による主な問題を以下に整理します。
| 問題 | 内容 |
|---|---|
| 有意差が出ない | 十分な差を検出できない |
| 結果が不安定 | 日ごとに勝者が変わる |
| 誤った勝者選択 | 偶然良く見えた案を採用してしまう |
| 検出力が低下 | 本当の効果を見逃す |
| 意思決定が曖昧 | 判断材料として使いにくい |
4.1 有意差が出ない
サンプル数が不足していると、A案とB案に実際の差があっても統計的有意差が出ないことがあります。これは、データ量が少ないために差を十分に検出できない状態です。
この場合、「差がない」と結論づけるのは危険です。正しくは、「現在のサンプル数では差を確認できない」と解釈する必要があります。
4.2 結果が不安定になる
サンプル不足の状態では、A/Bテストの結果が日ごとに大きく変わることがあります。ある日はA案が勝っていたのに、翌日にはB案が勝っているように見えるケースです。
これは、少数のユーザー行動が結果に大きく影響しているためです。安定した判断を行うには、一定期間データを集め、結果の推移を確認する必要があります。
4.3 誤った勝者選択
サンプル不足のままA/Bテストを終了すると、偶然良く見えたパターンを勝者として選んでしまう可能性があります。これにより、実際には効果のない施策を本番反映してしまうリスクがあります。
誤った勝者選択は、CVR低下やUX悪化につながることがあります。A/Bテストでは、途中結果だけで判断せず、事前に決めたサンプルサイズや実験期間を守ることが重要です。
5. サンプル過多問題
サンプル不足が問題になる一方で、サンプルが多すぎる場合にも注意が必要です。大量のデータがあると、非常に小さな差でも統計的に有意と判定されることがあります。
しかし、統計的に有意であることと、実務上意味があることは同じではありません。サンプル過多による主な問題を以下に整理します。
| 問題 | 内容 |
|---|---|
| 小さな差でも有意になる | 実務上ほぼ意味のない差を検出する |
| 意思決定が過剰になる | 小さな変化に反応しすぎる |
| 実験コストが増える | 長期間の実験で機会損失が発生する |
| 実務的意味を失う | 効果量の確認が不足する |
| 改善優先度を誤る | 重要でない差に注目してしまう |
5.1 小さすぎる差でも有意になる
サンプルサイズが非常に大きい場合、わずかなCVR差でも統計的に有意と判定されることがあります。たとえば、CVRが2.00%から2.03%に上がっただけでも、大規模サイトでは有意になる可能性があります。
しかし、その差が事業上意味のある改善かどうかは別問題です。A/Bテストでは、有意差だけでなく、改善幅、売上インパクト、実装コストも考慮する必要があります。
5.2 実務的意味を失う
統計的には正しい結果でも、実務的にはほとんど意味がない場合があります。小さな差を追い続けると、重要なUX改善や大きな成長施策にリソースを使えなくなる可能性があります。
そのため、A/Bテストでは最小検出効果を事前に決めることが重要です。どの程度の改善があれば実装する価値があるのかを明確にしておくことで、意味のある判断ができます。
5.3 コスト増加
サンプルを多く集めるには、時間やトラフィックが必要です。実験期間が長くなるほど、勝っていないパターンをユーザーに見せ続けることになり、機会損失が発生する可能性があります。
また、A/Bテストを長期間続けると、外部環境の変化も入りやすくなります。サンプル数を増やすことは重要ですが、必要以上に長く実験を続けることは避けるべきです。
6. ランダムサンプリング
ランダムサンプリングとは、実験対象のユーザーをできるだけ公平にA群とB群へ割り当てる方法です。A/Bテストでは、ランダム化によってユーザー属性の偏りを減らし、施策そのものの効果を比較しやすくします。
ランダムサンプリングが適切に行われていないと、テスト結果はバイアスの影響を受けます。以下に、ランダムサンプリングの役割を整理します。
| 役割 | 内容 |
|---|---|
| 均等分割 | A案とB案に公平にユーザーを割り当てる |
| バイアス軽減 | 属性や行動の偏りを抑える |
| 比較精度向上 | 施策効果を判断しやすくする |
| 実験公平性 | 片方の条件だけ有利になることを防ぐ |
| 再現性向上 | 結果の信頼性を高める |
6.1 ユーザーを均等に分割する
A/Bテストでは、ユーザーをAパターンとBパターンにできるだけ公平に分ける必要があります。一般的には、50対50でランダムに分割する方法が多く使われます。
ただし、単に人数を半分にするだけでは十分ではありません。新規ユーザー、既存ユーザー、デバイス、流入元などが大きく偏っていないかも確認する必要があります。
6.2 バイアスを減らす
ランダムサンプリングの目的は、ユーザー属性や行動傾向の偏りを減らすことです。偏りが少なければ、A案とB案の差を施策そのものの効果として解釈しやすくなります。
たとえば、B案に購買意欲の高いユーザーが多く含まれていると、B案の成果が高く見える可能性があります。ランダム化は、このような偏りを防ぐための基本的な仕組みです。
6.3 実験公平性を保つ
A/Bテストでは、比較する条件以外はできるだけ同じにする必要があります。デザインや文言以外の条件が違ってしまうと、どの要因が結果に影響したのか判断できません。
ランダムサンプリングは、実験の公平性を保つための重要な前提です。公平な実験設計があって初めて、A/Bテストの結果を意思決定に活用できます。
7. サンプル偏り問題
サンプル偏りとは、A/Bテストに参加するユーザーが母集団を正しく反映していない状態です。特定のユーザー層、デバイス、地域、流入経路に偏ると、結果を全体に適用できなくなります。
A/Bテストでは、サンプル数だけでなく、サンプルの中身も重要です。代表的なサンプル偏りを以下に整理します。
| 偏り | 内容 | 起こりうる問題 |
|---|---|---|
| 特定ユーザー偏重 | 新規・既存・ヘビーユーザーなどに偏る | 結果を全体に適用できない |
| デバイス差異 | PC・スマホ比率が偏る | UI改善効果を誤解する |
| 流入経路差異 | 広告・SNS・検索の比率が偏る | 施策効果を誤認する |
| 地域差異 | 特定地域ユーザーが多い | ニーズを誤認する |
| 時間帯差異 | 特定時間帯の利用者に偏る | 通常時の行動とズレる |
7.1 特定ユーザー偏重
A/Bテストで特定のユーザー層だけが多く含まれると、結果の解釈が難しくなります。たとえば、ヘビーユーザーが多いサンプルでは、複雑なUIでも問題なく利用される可能性があります。
しかし、新規ユーザーやライトユーザーにとっては、同じUIがわかりにくい場合があります。全体向けの改善を判断する場合は、サンプルが特定層に偏っていないか確認する必要があります。
7.2 デバイス差異
スマートフォンとPCでは、画面サイズ、操作方法、利用シーンが異なります。そのため、同じ変更でもデバイスによって効果が変わることがあります。
モバイルユーザーが多いサンプルで良い結果が出ても、PCユーザーでも同じ効果があるとは限りません。A/Bテストでは、デバイス別に結果を確認することが重要です。
7.3 流入経路差異
ユーザーの流入経路によって、行動目的や購買意欲は大きく異なります。検索流入ユーザーは明確な目的を持っていることが多く、SNS流入ユーザーは一時的な興味で訪問している場合があります。
流入経路が偏ると、A/Bテストの結果もその影響を受けます。広告キャンペーン中やSNSで話題になった直後のデータは、通常時のユーザー行動とは分けて考える必要があります。
8. セグメント別サンプル
セグメント別サンプルとは、ユーザーを属性や行動条件ごとに分けて分析する考え方です。A/Bテストでは、全体結果だけでなく、新規ユーザー、リピーター、地域、デバイス別に結果を見ることで、より正確な判断ができます。
全体では改善しているように見えても、一部の重要セグメントでは悪化している場合があります。セグメント別に確認すべき観点を以下に整理します。
| セグメント | 見るべきポイント |
|---|---|
| 新規ユーザー | 初回体験、登録率、初回CVR |
| リピーター | 継続率、再購入率、利用頻度 |
| 地域別 | ニーズ、文化、配送条件、価格感覚 |
| デバイス別 | UI操作性、表示崩れ、クリック率 |
| 流入元別 | 購買意欲、滞在時間、CVR |
8.1 新規ユーザー
新規ユーザーは、サービスや商品の理解がまだ浅い状態で訪問します。そのため、LPの説明、登録導線、初回操作のわかりやすさが成果に大きく影響します。
A/Bテストで新規ユーザーのサンプルが少ない場合、初回体験への影響を正しく判断できません。新規獲得を目的とする施策では、新規ユーザーだけの結果を必ず確認する必要があります。
8.2 リピーター
リピーターは、すでにサービスを理解しているユーザーです。新規ユーザーとは異なり、操作に慣れているため、小さなUI変更にも敏感に反応する場合があります。
リピーター向けのA/Bテストでは、短期的なCVRだけでなく、継続率や再購入率も確認することが重要です。既存ユーザーの体験を悪化させる変更は、長期的な売上に影響する可能性があります。
8.3 地域・デバイス別分析
地域やデバイスによって、ユーザー行動は大きく変わります。地域によって価格感覚や配送条件が異なる場合があり、デバイスによって操作性や表示の見え方も変わります。
A/Bテストでは、全体平均だけでなく、地域別・デバイス別の結果を見ることで、特定環境での問題を発見しやすくなります。特にモバイル比率が高いサービスでは、スマホUXの確認が欠かせません。
9. 実験期間との関係
A/Bテストのサンプルは、実験期間とも深く関係しています。短すぎる期間では十分なサンプルが集まらず、曜日差や時間帯差の影響を強く受ける可能性があります。
一方で、長すぎる期間では外部環境の変化が入りやすくなります。適切な実験期間を設計するために、以下の観点を確認する必要があります。
| 観点 | 内容 |
|---|---|
| 短期間の問題 | サンプル不足や曜日偏りが起きやすい |
| 長期間の問題 | 外部要因が入りやすい |
| 曜日差 | 平日・休日で行動が変わる |
| 季節性 | セール、連休、イベントの影響を受ける |
| 安定性 | 結果が一定しているか確認する |
9.1 短期間では不十分
A/Bテストを短期間で終了すると、十分なサンプルが集まらない可能性があります。特にCVRが低いサービスでは、数日間のデータだけでは判断に必要なコンバージョン数が不足しがちです。
短期間の結果は、偶然や一時的な流入に大きく左右されます。テスト開始直後に片方のパターンが良く見えても、それだけで勝者を決めるのは危険です。
9.2 曜日差・季節性考慮
ユーザー行動は曜日や季節によって変わります。平日と休日ではアクセス時間や購買意欲が異なることがあり、月末、連休、セール期間なども行動に影響します。
そのため、A/Bテストでは最低でも1週間以上実施し、曜日差を含めて判断することが望ましい場合があります。季節性の強いサービスでは、通常期間と特殊期間を分けて考える必要があります。
9.3 安定データ収集
A/Bテストでは、サンプル数だけでなく、結果が安定しているかも重要です。日ごとに勝者が入れ替わるような状態では、まだ判断に十分なデータが集まっていない可能性があります。
安定したデータ収集のためには、事前に実験期間と必要サンプル数を決めておくことが大切です。途中結果に振り回されず、計画通りに実験を進めることで、信頼性の高い判断ができます。
10. サンプルサイズ計算
A/Bテストでは、実験を始める前に必要なサンプルサイズを計算しておくことが重要です。サンプルサイズを事前に見積もることで、どれくらいの期間テストを行うべきか判断しやすくなります。
サンプルサイズ計算では、現在のCVR、検出したい改善幅、信頼水準、検出力などを使います。主な要素を以下に整理します。
| 要素 | 内容 |
|---|---|
| ベースCVR | 現在のコンバージョン率 |
| 最小検出効果 | 検出したい最小の改善幅 |
| 信頼水準 | 偶然ではないと判断する基準 |
| 検出力 | 本当の差を見つける力 |
| 割り当て比率 | A/Bのサンプル分配割合 |
10.1 必要サンプル数を予測する
A/Bテストを始める前に、必要なサンプル数を予測しておくことで、早期終了やサンプル不足を防げます。必要数を知らずに実験を始めると、結果が出る前に判断してしまう危険があります。
必要サンプル数は、検出したい差が小さいほど大きくなります。小さなCVR改善を正確に検出したい場合、多くのユーザーと長い実験期間が必要になります。
10.2 ベースCVRを使う
サンプルサイズ計算では、現在のCVRであるベースCVRが重要になります。たとえば、現在のCVRが1%なのか10%なのかによって、必要なサンプル数は大きく変わります。
CVRが低い場合、コンバージョン数を十分に集めるために多くのアクセスが必要です。A/Bテストでは、単なる訪問者数だけでなく、コンバージョン数も意識する必要があります。
10.3 最小検出効果を決める
最小検出効果とは、A/Bテストで検出したい最小の改善幅です。たとえば、CVRを2.0%から2.2%に改善したいのか、2.0%から3.0%に改善したいのかで必要サンプル数は変わります。
最小検出効果を決めずにA/Bテストを行うと、小さすぎる差に過剰反応したり、必要なデータ量を見誤ったりします。実務上意味のある改善幅を事前に定義しておくことが大切です。
11. 統計的有意性との関係
統計的有意性とは、A/Bテストで観測された差が偶然によるものか、それとも実際の施策効果によるものかを判断する考え方です。サンプルサイズは、この統計的有意性に大きく影響します。
サンプルが少なすぎると有意差が出にくくなり、多すぎると小さな差でも有意になりやすくなります。統計的有意性に関係する主な指標を以下に整理します。
| 指標 | 内容 |
|---|---|
| p値 | 観測された差が偶然起きる確率の目安 |
| 信頼区間 | 推定値の不確実性を示す範囲 |
| 検出力 | 本当の差を見つける力 |
| 効果量 | 差の大きさを示す |
| サンプルサイズ | これらの指標に大きく影響する |
11.1 p値に影響する
p値は、A/Bテストでよく使われる統計指標です。サンプルサイズが大きいほど、同じ差でもp値は小さくなりやすく、統計的に有意と判定されやすくなります。
ただし、p値だけで判断するのは危険です。p値が小さくても、改善幅が非常に小さければ実務上の意味は薄い場合があります。
11.2 信頼区間を左右する
信頼区間は、推定されたCVRや差分がどの範囲に収まりそうかを示す指標です。サンプルサイズが大きいほど信頼区間は狭くなり、推定の精度が上がります。
サンプルサイズが小さい場合、信頼区間は広くなり、結果の不確実性が高くなります。A/Bテストでは、単一の数値だけでなく、信頼区間を見ることで判断の安定性を確認できます。
11.3 検出力に関係する
検出力とは、本当に差がある場合に、その差を正しく検出できる力です。サンプルサイズが不足していると検出力が低くなり、効果のある施策を見逃す可能性があります。
A/Bテストで「差がない」と判断する場合も、検出力が十分だったかを確認する必要があります。検出力が低い状態では、差がないのではなく、差を見つけるだけのデータが足りなかった可能性があります。
12. UX分析との関係
A/Bテストのサンプル設計は、UX分析にも大きく関係します。UX改善の効果を正しく評価するには、対象ユーザーが適切であり、十分なサンプルが集まっている必要があります。
UXは短期的なCVRだけでなく、継続率、満足度、操作性、離脱率などにも関係します。UX分析とサンプルの関係を以下に整理します。
| 観点 | 内容 |
|---|---|
| UX改善効果 | UI変更が本当に効果を出したか確認する |
| 行動分析 | クリック、スクロール、離脱などを分析する |
| 長期体験 | 継続率や再訪率への影響を見る |
| セグメント差 | 初心者・既存ユーザーで効果を見る |
| 定量と定性 | 数値とユーザーの声を組み合わせる |
12.1 UX改善効果の信頼性
UX改善を目的としたA/Bテストでは、サンプル設計が結果の信頼性を左右します。たとえば、ボタン配置を変更した場合、クリック率が上がったとしても、それが本当にUX改善によるものか確認する必要があります。
サンプルが偏っていると、一部ユーザーにだけ効果がある改善を全体に適用してしまう可能性があります。UX改善では、全体結果だけでなく、ユーザー層別の反応を見ることが重要です。
12.2 行動分析精度向上
A/Bテストでは、CVRだけでなく、クリック率、スクロール率、離脱率、滞在時間などの行動データも分析できます。これにより、ユーザーがどこで迷い、どこで行動を起こしているのかを把握できます。
ただし、行動分析もサンプルの影響を受けます。少数のユーザー行動だけで判断すると、実際のUX課題を誤って解釈する可能性があります。
12.3 長期体験評価
UX改善は、短期的なCVRだけでは評価できない場合があります。ある変更によって初回CVRが上がっても、長期的な満足度や継続率が下がる可能性があります。
そのため、UX分析では短期指標と長期指標の両方を見ることが重要です。A/Bテストのサンプル設計でも、必要に応じてリピーターや継続利用者を含めた評価が求められます。
13. よくある失敗
A/Bテストでは、サンプル設計に関する失敗が多く発生します。特に、早期終了、サンプル不足、一部ユーザーだけの分析、有意差だけを見る判断は、誤った意思決定につながりやすいです。
実務でよくある失敗を知っておくことで、A/Bテストの精度を高めやすくなります。代表的な失敗を以下に整理します。
| 失敗 | 内容 |
|---|---|
| 早期終了 | 十分なサンプルが集まる前に判断する |
| 一部ユーザーだけ分析 | 偏ったサンプルで結論を出す |
| サンプル不足無視 | 検出力が低いまま判断する |
| 外部要因無視 | キャンペーンや季節性を考慮しない |
| 有意差だけを見る | 実務上の意味を確認しない |
13.1 早期終了
A/Bテストでよくある失敗のひとつが、途中結果を見て早期終了することです。開始直後にB案が勝っているように見えると、すぐにB案を採用したくなることがあります。
しかし、初期の結果は偶然の影響を強く受けます。事前に決めたサンプルサイズや実験期間を満たす前に判断すると、誤った勝者を選ぶ可能性があります。
13.2 一部ユーザーだけ分析
一部のユーザーだけを見てA/Bテストの結論を出すことも危険です。たとえば、モバイルユーザーだけの結果を全体に適用すると、PCユーザーの体験を悪化させる可能性があります。
セグメント分析は重要ですが、一部セグメントの結果を全体の結論として扱う場合は注意が必要です。どの範囲に適用できる結果なのかを明確にすることが大切です。
13.3 サンプル不足無視
サンプル不足を無視すると、A/Bテストの結果は不安定になります。十分なデータがないまま「差がない」と判断したり、偶然良く見えた案を採用したりする危険があります。
特にCVRが低いサービスでは、必要なコンバージョン数が集まるまで時間がかかります。訪問者数だけでなく、実際のCV数も確認する必要があります。
13.4 外部要因を考慮しない
A/Bテスト中に広告キャンペーン、セール、SNS拡散、システム障害などが発生すると、ユーザー行動が大きく変わることがあります。これらを考慮しないと、施策効果を誤って評価する可能性があります。
外部要因がある場合は、期間を分けて分析する、該当期間を除外する、流入元別に見るなどの対応が必要です。A/Bテストは、実験環境の変化にも注意して解釈する必要があります。
13.5 有意差だけを見る
有意差が出たからといって、必ずしも実装すべきとは限りません。改善幅が小さすぎる場合や、実装コストが高い場合、ビジネス上の価値が低い可能性があります。
A/Bテストでは、有意差、効果量、売上インパクト、UX影響、実装コストを総合的に判断する必要があります。統計的に正しいだけではなく、実務的に意味のある判断が重要です。
14. サンプル管理のベストプラクティス
A/Bテストの精度を高めるには、サンプル管理の基本を押さえる必要があります。実験前の設計、ランダム化、セグメント確認、実験期間の管理が重要です。
サンプル管理を丁寧に行うことで、A/Bテストの結果をより安心して意思決定に活用できます。主なベストプラクティスを以下に整理します。
| ベストプラクティス | 内容 |
|---|---|
| 必要数を事前計算 | 実験前にサンプルサイズを見積もる |
| ランダム化 | ユーザーを公平に割り当てる |
| セグメント分析 | ユーザー層別に結果を確認する |
| 実験期間管理 | 短すぎる・長すぎる実験を避ける |
| 結果の総合判断 | 有意差だけでなく実務効果を見る |
14.1 実験前に必要数を計算する
A/Bテストを始める前に、必要なサンプル数を計算しておくことが重要です。これにより、どれくらいの期間テストを行う必要があるのかを事前に把握できます。
必要数を決めずにテストを始めると、途中結果に振り回されやすくなります。実験前に判断基準を明確にしておくことで、より客観的な意思決定ができます。
14.2 ランダム化を徹底する
A/Bテストでは、ユーザーの割り当てをランダム化することが基本です。ランダム化によって、A案とB案に含まれるユーザー属性の偏りを減らすことができます。
ただし、ランダム化していても、サンプルサイズが小さい場合は偶然偏りが出ることがあります。分割後に属性分布を確認し、大きな偏りがないかを見ることも大切です。
14.3 セグメント分析を行う
全体結果だけで判断せず、セグメント別に結果を確認することが重要です。新規ユーザー、既存ユーザー、デバイス、地域、流入元ごとに見ることで、どの層に効果があるのかを把握できます。
ただし、セグメントを細かく分けすぎると、それぞれのサンプル数が不足する場合があります。セグメント分析では、意味のある切り口と十分なデータ量のバランスが必要です。
15. A/Bテストのサンプル設計の本質
A/Bテストのサンプル設計の本質は、信頼できる意思決定のために、適切なデータを適切な方法で集めることです。サンプル数だけでなく、サンプルの質、分割方法、偏り管理、実験期間が重要になります。
A/Bテストは単なる数値比較ではなく、仮説検証のための仕組みです。サンプル設計が不十分であれば、どれだけ見た目の良い結果が出ても信頼できません。
サンプル設計の本質を整理すると、以下のようになります。
| 本質 | 内容 |
|---|---|
| サンプル品質 | 結果の信頼性を決める |
| データ量 | 偶然の影響を減らす |
| 偏り管理 | 結果の適用範囲を明確にする |
| UXと統計 | 数値と体験の両方を見る |
| 意思決定基盤 | 施策判断の根拠になる |
15.1 サンプル品質が結果品質を決める
A/Bテストの結果品質は、サンプル品質によって決まります。サンプル数が十分でも、対象ユーザーが偏っていれば、結果を全体に適用することはできません。
質の高いサンプルとは、母集団を適切に反映し、ランダムに分割され、必要な数が確保されているデータです。A/Bテストでは、実験内容と同じくらいサンプル設計が重要です。
15.2 データ量だけでは不十分
A/Bテストでは、データ量が多ければ安心と思われがちです。しかし、データ量が多くても、特定ユーザーや特定期間に偏っていれば、結果は歪みます。
重要なのは、量と質の両方です。十分なサンプルサイズを確保しながら、サンプルの代表性や偏りも確認する必要があります。
15.3 偏り管理が重要
A/Bテストでは、サンプル偏りを完全になくすことは難しいですが、把握して管理することは可能です。ユーザー属性、デバイス、流入元、地域、時間帯などを確認することで、結果の適用範囲を明確にできます。
偏りを無視すると、一部ユーザーにだけ有効な施策を全体に展開してしまう可能性があります。偏りを理解したうえで判断することが、実験精度を高めるポイントです。
15.4 UXと統計の両立が必要
A/Bテストでは、統計的に正しいだけでなく、UXとして良い改善かどうかも確認する必要があります。短期的にCVRが上がっても、ユーザー体験が悪化していれば長期的な成果につながらない可能性があります。
そのため、A/Bテストでは数値指標とUX観点を組み合わせて判断することが重要です。クリック率やCVRだけでなく、離脱率、継続率、ユーザー満足度なども確認することで、より良い意思決定ができます。
15.5 正しい意思決定の基盤になる
A/Bテストのサンプル設計は、正しい意思決定の基盤です。適切なサンプルがあれば、施策の効果をより正確に評価し、改善の優先順位を決めやすくなります。
逆に、サンプル設計が不十分なA/Bテストは、データに基づいているように見えても、実際には誤った判断につながる可能性があります。信頼できる実験には、信頼できるサンプル設計が不可欠です。
おわりに
A/Bテストにおけるサンプルは、実験結果の信頼性を左右する重要な要素です。サンプルサイズが少なすぎると偶然の影響を受けやすくなり、十分な差を検出できない可能性があります。
一方で、サンプルが多すぎる場合にも注意が必要です。非常に小さな差でも統計的に有意になることがあり、実務上意味のある改善かどうかを見極める必要があります。
A/Bテストでは、サンプル数だけでなく、ランダム分割、サンプル偏り、セグメント別分析、実験期間、外部要因の確認が重要です。特にUX改善を目的とする場合は、短期的なCVRだけでなく、長期的なユーザー体験への影響も考える必要があります。
正しいA/Bテストを行うには、「どれだけのデータを集めるか」だけでなく、「誰のデータを集めるか」「どのように分割するか」「どこまで結果を適用できるか」を意識することが大切です。
プロダクト改善やマーケティングでは、データ品質、UX理解、統計的な実験設計を組み合わせたA/Bテスト運用がますます重要になります。サンプル設計を正しく行うことは、精度の高い仮説検証と、信頼できる意思決定の第一歩です。