 EN
EN JP
JP KR
KR
The History of GPT: A Journey Through Generative Pre-trained Transformers
The Generative Pre-trained Transformer (GPT) series, developed by OpenAI, has revolutionized the field of natural language processing (NLP). Let's explore the history and technical aspects of these groundbreaking models.
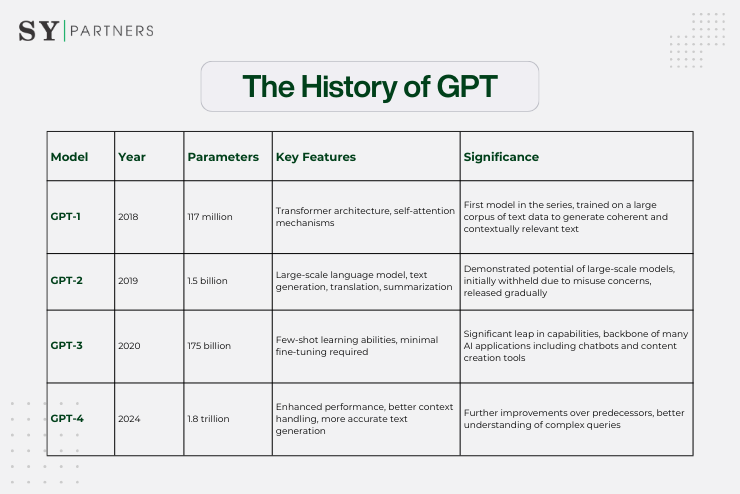
1. The History of GPT
1.1 GPT-1: The Beginning
Introduced in 2018, GPT-1 was the first model in the series. It utilized the Transformer architecture, which relies on self-attention mechanisms to process and generate text. GPT-1 was trained on a large corpus of text data, enabling it to generate coherent and contextually relevant text based on the input it received.
1.2 GPT-2: Scaling Up
In 2019, OpenAI released GPT-2, which significantly increased the model's size and capabilities. With 1.5 billion parameters, GPT-2 demonstrated the potential of large-scale language models to perform a variety of tasks, such as text generation, translation, and summarization.
However, due to concerns about misuse, OpenAI initially withheld the full model, releasing it gradually over time.
1.3 GPT-3: The Game Changer
GPT-3, released in 2020, marked a significant leap in the capabilities of language models. With 175 billion parameters, GPT-3 could perform tasks with minimal fine-tuning, showcasing impressive few-shot learning abilities
This model became the backbone of many AI applications, including chatbots, content creation tools, and more.
1.4 GPT-4: The Latest Advancement
The latest in the series, GPT-4, released in 2024, further improved on its predecessors with enhanced performance and capabilities. GPT-4's advancements include better handling of context, more accurate text generation, and improved understanding of complex queries.
2. Technical Aspects of GPT Models
2.1 Transformer Architecture
At the core of GPT models is the Transformer architecture, introduced by Vaswani et al. in 2017. Transformers use self-attention mechanisms to process input sequences, allowing the model to weigh the importance of different words in a sentence, regardless of their position.
2.2 Self-Attention Mechanism
The self-attention mechanism enables each word in the input to attend to every other word, capturing dependencies and relationships across the entire sequence. This is crucial for understanding context and generating coherent text.
2.3 Training Process
GPT models are pre-trained on vast amounts of text data using unsupervised learning. This involves predicting the next word in a sentence, allowing the model to learn language patterns and structures. Fine-tuning on specific tasks can further enhance the model's performance.
2.4 Tokenization
Tokenization is the process of converting text into smaller units called tokens. GPT models use byte pair encoding (BPE) to tokenize text, which helps in handling rare words and subword units effectively.
Conclusion
The GPT series has transformed the landscape of NLP, pushing the boundaries of what AI can achieve in understanding and generating human-like text. From GPT-1 to GPT-4, each iteration has brought significant advancements, making these models indispensable tools in various applications.
By understanding the history and technical aspects of GPT models, we can appreciate the remarkable progress in AI and its potential for future innovations.






