EN
EN JP
JP KR
KR
データ・エンジニアリング
当社は、効率的で信頼性の高いデータパイプラインとインフラストラクチャを構築し、貴社のデータ活用を次のレベルへ導きます。カスタマイズされたデータエンジニアリングサービスで、競争優位を確立しましょう。
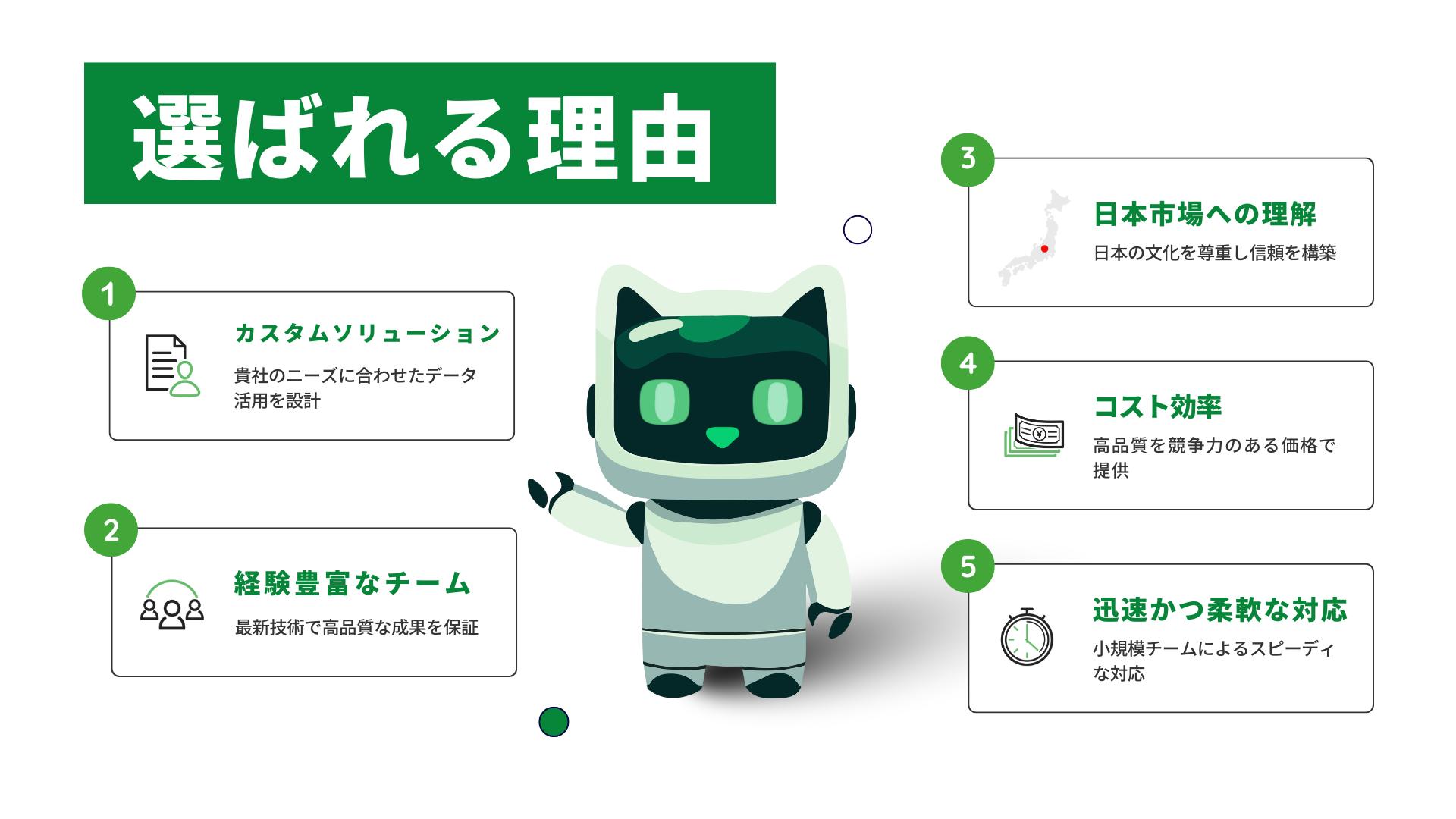
私たちのデータエンジニアリングサービスは、業界を問わず貴社のデータ活用をサポートします。
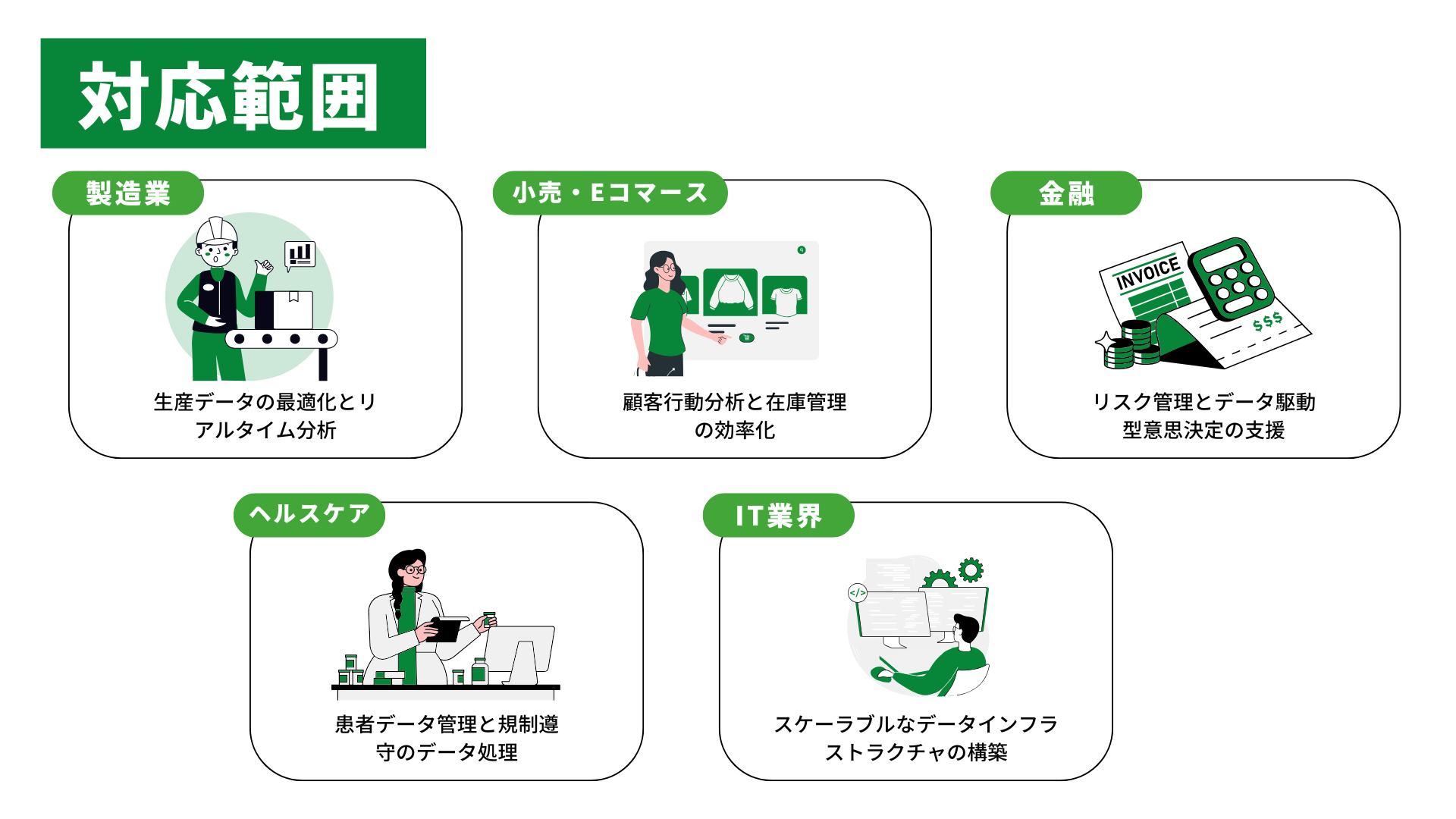
その他、貴社の業界特有のニーズにも柔軟に対応します。
私たちは、業界標準のツールとプラットフォームを活用し、効率的でスケーラブルなデータソリューションを提供します。
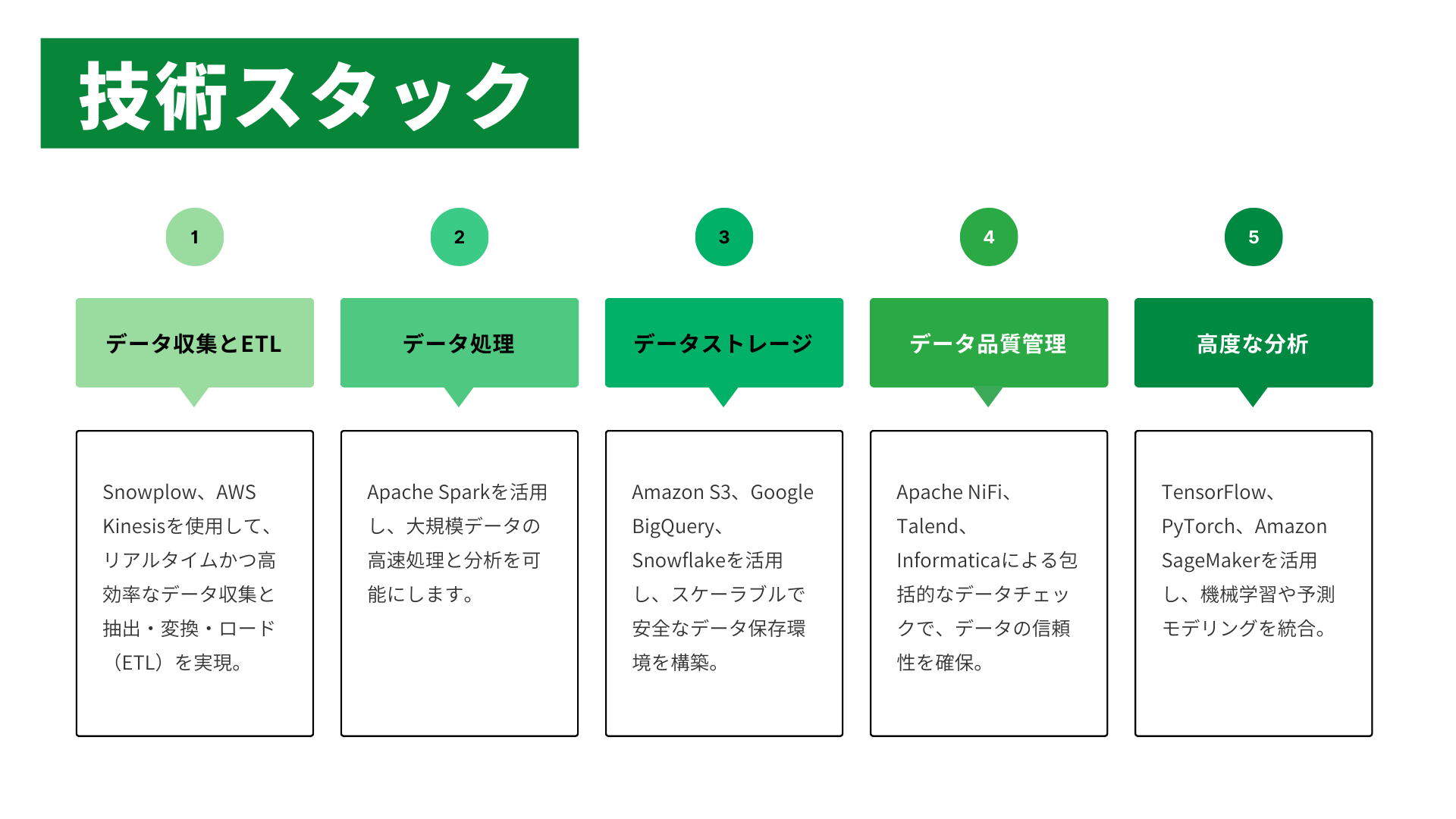
貴社の既存システムとの統合もスムーズに行い、最新技術を最大限に活用します。

| ステップ | タイトル | 説明 |
|---|---|---|
| 1 | 要件定義 | 貴社のビジネス目標とデータ課題をヒアリングし、最適なソリューションを設計します。 |
| 2 | データ収集とETL | SnowplowやAWS Kinesisを活用し、リアルタイムで効率的なデータパイプラインを構築します。 |
| 3 | データ処理 | Apache Sparkを使用して、大規模データの高速処理と変換を行い、分析可能なデータセットを生成します。 |
| 4 | データストレージ | Amazon S3、Google BigQuery、Snowflakeを活用し、スケーラブルで安全なデータ保存環境を構築します。 |
| 5 | データ品質の保証 | 包括的なデータチェックとクレンジングで、データの正確性と信頼性を確保します。 |
| 6 | 高度な分析の統合 | 機械学習や予測モデリングを導入し、データから価値ある洞察を引き出します。 |
| 7 | 継続的なサポート | 運用後のメンテナンスと最適化を行い、貴社のデータ活用を長期的に支援します。 |
実績
Piカスタマーデータプラットフォーム
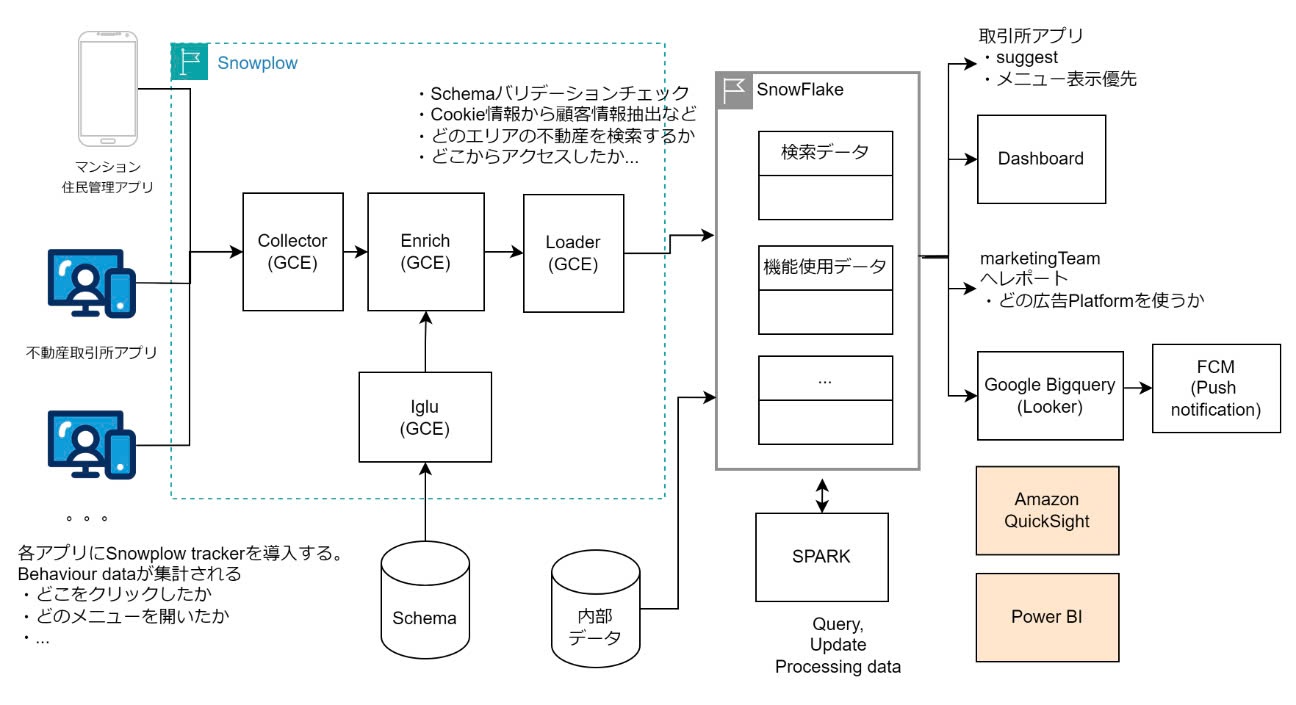
- 概要: 色んなWeb・Appからデータを統計して営業チーム、マーケティングチーム、カスタマーサポートセンター向けのデータを提供する。
技術スタック:Snowplow、Snowflake、Spark
当社と提携することで、データを戦略的な資産に変換し、業界で競争優位を得ることができます。 データエンジニアリングサービスの詳細は、ぜひお問い合わせください。